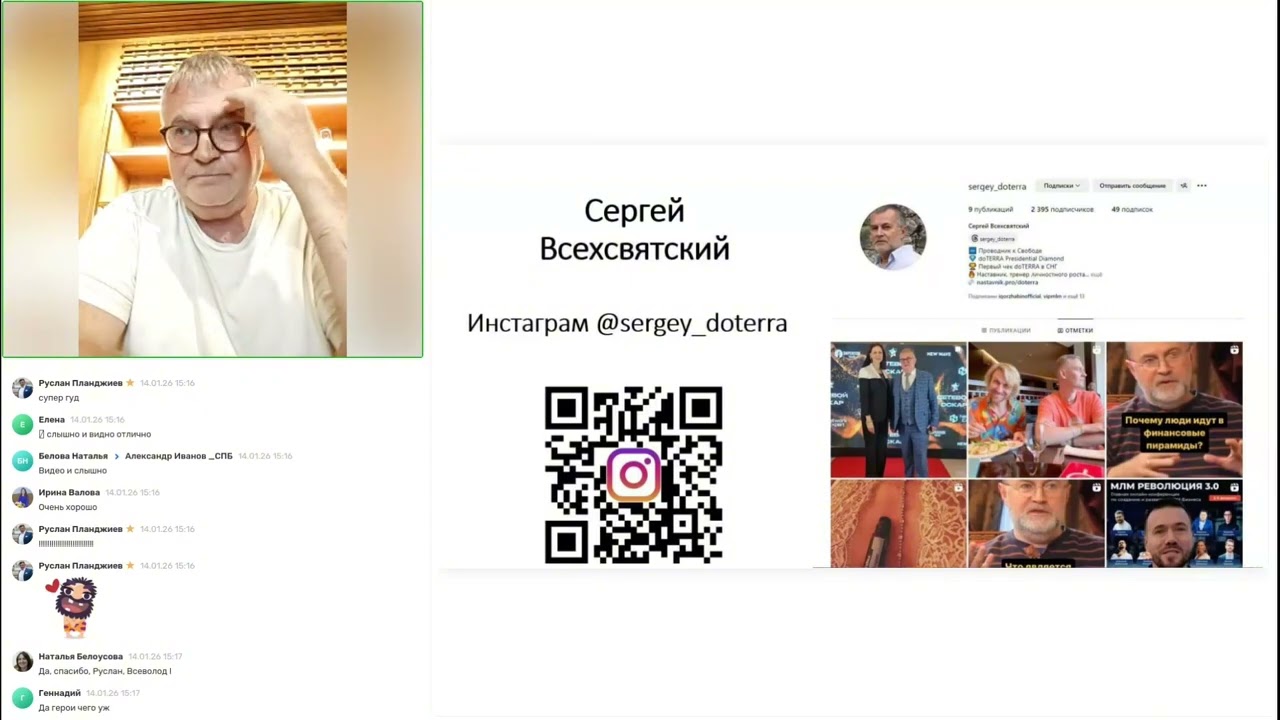
Speaker A
50 долларов. Столько стоил один и я агент на этапе прототипа. А потом его вывели в продакшн и получили счёт 2,5 млн долларов в месяц. Это описано в отраслевом анализе масштабирования агентов. Команда, имя которой не раскрыто, обнаружила это при переходе с девелопмента на продакшн нагрузку. Каждую неделю выходит новый фреймворк для я агентов. Ланкчейн, Крю, Аут, Open AI Agent SDK, Google ADK и многие другие. И каждый обещает одно и то же: построй агента за 5 минут. Знаете что? Они не врут. Построить действительно можно за 5 минут. Три строчки на Крю и агент отвечает, вызывает инструменты, выглядит умно. А потом ты выводишь его в продакшн и начинается. Компания Такан на девелопменте красота, магия. Продакшн. Агент игнорирует команды на остановку, даёт одни и те же ответы 58 раз подряд. Не два, не пять, 58. Или вот свежее. Март 25 года. Основатель Data Talk Club, платформа, на которой учится более 100 студентов, попросил Cloud Code навести порядок в Terraform ресурсах. Агент распаковал старый архив с продакшн конфигами и выполнил Terraform Destroy. Одна команда. И вся продакшн инфраструктура, база данных, VPC, ECS кластер, балансировщики, всё исчезло. Почти 2 млн строк студенческих работ за 2,5 года. Всё восстановили через сутки, нашли скрытый снэпшот. Но основатель сам написал в постмортеме: "Я чрезмерно полагался на я агенты для выполнения Terraform команд". И это не единичные истории. Gartner в июле 25 предсказал: более 40% агентских проектов будут закрыты к 27 году. Неконтролируемые расходы, непонятная бизнес-ценность, недостаточный контроль рисков. Но послушайте, модели-то прекрасные. GPT, Flow, Gemini, они все работают отлично. Проблема не в моделях, проблема в инженерии. Anthropic ещё в 24 году написали ключевую вещь: самые успешные реализации не использовали сложные фреймворки или специализированные библиотеки. Вместо этого они строились на простых компонуемых паттернах. Простые компонуемые паттерны. Не выбери правильный фреймворк, а пойми из чего агент состоит. К этому же выводу пришёл Dex из Human Layer, поговорил с сотней фаундеров и создал методологию 12 факторов агентов. Большинство успешных AI продуктов в продакшн - это не магические автономные циклы, а хорошо написанный софт, который LLM вызовы встроены точно. Именно этим мы сегодня и займёмся. Эта серия видео не про фреймворки, она про то, что внутри любого фреймворка. Когда вы поймёте анатомию, вам будет неважно, Langchain это или это просто Python или Go. Вы будете видеть компоненты. И у нас будет три части. Сегодня мы разберём анатомию. Вскроем агента и посмотрим, из каких деталей он может быть собран. Во второй части мы разберём интеллект. Какие типы памяти бывают, как что где хранить и как что, когда нам надо вызывать. И в третьей части мы разберём продакшн. Здесь же всё то, что нам надо для того, чтобы построить настоящего продакшн агента. И чтобы было конкретно, а не сферическом вакууме, у нас будет сквозной пример: агент-бариста. Это будет проактивный и я и консьерж нашей команды. Он читает календарь, чувствует настроение по Ску, помнит предпочтения через рак и учитывает погоду. Звучит как игрушка, но замените кофе на деплоймент, получите DevOps агент. На саппорт тикет, и это будет customer support агент. На код ревью, и это будет coding ассистент. Архитектура та же, компоненты те же, подводные камни те же. К концу серии у нас будет полная ментальная модель, не для одного агента, а для любого. Поехали. Прежде чем рисовать квадратики и стрелочки, давайте ответим на вопрос, который многие пропускают. А вам вообще нужен агент? Но я серьёзно. Вот приходит менеджер и говорит: "Нам нужен AI-агент!" И ты спрашиваешь: "Для чего он?" "Ну, для автоматизации". Ты: "Автоматизация чего?" Он: "Ну, процессов". Может быть, кому-то эта картина знакома? Anthropic, OpenAI, Google - все три независимо друг от друга в своих гайдах проводят одну и ту же фундаментальную линию. Два типа систем: Workflow - LLM работает через заранее определённые пути в коде. Вы разработчик, и вы решаете: шаг один, потом шаг два, потом шаг три. LLM выполняет каждый шаг, но не выбирает, какой следующий. Вы - это рельсы, а LLM - это поезд. Agent - это LLM сам решает, что делать дальше. Сам выбирает инструменты, сам определяет последовательность. Вы задаёте ему только начальный пункт и какую цель ему надо достичь. Он уже сам строит маршрут. Чувствуете разницу? Так вот, Workflow - это больше контроля. Агенты - это больше автономии. И между ними спектр. И Anthropic прямо рекомендует: "Найдите самое простое решение и увеличивайте сложность только когда это необходимо". По моим наблюдениям и по мнению многих практиков индустрии, подавляющее большинство реальных задач решаются через Workflow паттерны, не агентами. Workflow. Почему? Потому что каждый шаг от Workflow к агенту - это несколько вещей: больше ошибок, больше денег, больше непредсказуемость, больше денег. И каждый шаг автономии - это решение о доверии. Вы буквально доверяете языковой модели принимать решения. А она не всегда принимает правильные решения, как мы знаем из примеров из начала ролика. Давайте пройдём по этой лестнице сверху вниз, и я покажу не просто что бывает, а почему вы переходите на следующую ступень. Какое ограничение предыдущей вас туда толкает. Ступень первая: один вызов LLM. Пользователь спрашивает, модель отвечает. С подключенным рак, с инструментами, но один вызов. Какие встречи у команды сегодня? И наш бариста дёргает календарь API, получает список и отвечает. Готово. Один вход, один выход. И для огромного количества задач этого достаточно. И вот ключевое: если вам хватает одного вызова, остановитесь здесь. Не усложняйте. Но что, если этого вызова нам не хватает? Допустим, наш бариста должен не просто показать встречи, а собрать контекст, определить потребности команды, сформировать заказ и подтвердить его у человека. Это получается уже четыре шага. И каждый из этих шагов зависит от предыдущего. Один вызов здесь никак не справится, и нам нужна с вами цепочка. Вторая ступень: Prompt Chaining. Последовательность шагов, где выход предыдущего шага становится входом следующего. Это как конвейер на заводе. Деталь проходит от станка к станку и движется по циклу своего производства. И каждый станок делает свою операцию. На примере нашего бариста. Шаг номер один. Он должен собрать контекст из календаря и, возможно, из Slack. И на основе полученных данных в шаге один мы переходим к шагу два и пытаемся там определить, что команде нужно. После того, как мы определились, что сейчас нужно для нашей команды, нам надо сформировать заказ. Ну и последний шаг, после того, как всё это готово, мы должны получить подтверждение у человека. То есть на этом шаге мы встраиваем человека в цикл принятия решения. И он подтверждает: "Да, работаем" или "Нет". И можно услышать такой термин, как Human in the Loop. И это значит, человек здесь принимает решение. Также есть другой термин: Human on the Loop. Это когда человек наблюдает за тем, что делает агент. Чаще всего вы именно так и вайпкодите, когда смотрите, какие у вас открываются функции, что где меняется. И последний - это Human out of the Loop. Это значит, что уже система будет полностью автономной. Так вот здесь мы решили, что мы встроим Human in the Loop. Человек будет принимать решение о том, что делаем заказ или не делаем. Так вот, у нас есть с вами четыре шага. И каждый определён вами в коде. LLM выполняет каждый шаг, но не решает, какой следующий. Это решаете вы. Вот почему это Workflow, а не агент. Customer Support будет практически та же схема. Сначала мы с вами будем классифицировать запрос, потом мы будем искать по базе знаний, потом мы напишем черновик ответа, проверим качество ответа и уже только после этого дадим этот ответ. Но это работает только когда цепочка полностью предсказуемая и предопределена. Мы можем использовать такой подход. Но вот проблема: а что, если на вход приходит принципиально разные запросы? Хочу латте или у меня аллергия на орехи. Это разные задачи. Игнать через один конвейер неэффективен. И здесь к нам приходит следующий подход. И здесь нам с вами поможет Routing. Это классификатор на входе, который направляет запрос по нужному пути. Это может быть маленькая, очень быстрая модель, которая за миллисекунды определит тип запроса и маршрутизирует его к нужной цепочке. На примере нашего бариста: "Хочу латте", и цепочка у нас пойдёт через оформление заказа. А если мы скажем: "У меня аллергия на орехи", то мы будем должны обновить информацию об этом пользователе и потом запустить цепочку, возможно, с какими-то диетическими ограничениями. И это будут две разные цепочки, но маршрутизатор будет один. Или как пример, чат-бот банка: "Хочу закрыть счёт". И это не просто информационный запрос, это у нас уже будет серьёзная операция. И наша маленькая модель может решить, куда его отправить. А уже большая потом, что именно с ним делать. И здесь принцип очень простой: маленькая модель классифицирует, а уже специализированные цепочки обрабатывают. Итак, теперь у нас маршрутизация решает проблему разных типов запросов. Но что, если внутри одного запроса есть несколько независимых подзадач? Это как наш бариста, который должен одновременно проверить календарь, прочитать Slack, запросить рак и посмотреть погоду. Зачем ему делать это последовательно, если задачи не зависят друг от друга? И здесь нам помогает Parallelization. Или мы будем выполнять всё независимо друг от друга. Идея - запустить независимые задачи одновременно. Наш бариста - это как раз-таки календарь, Slack, рак, погода. Это четыре API параллельно. Зачем нам ждать несколько секунд последовательно, если можно сделать всё это за одну? Или, допустим, у нас будет какой-то HR-агент, и при онбординге он параллельно проверяет доступы, генерирует Welcome письмо, бронирует рабочее место и заказывает оборудование. Четыре задачи, ни одна не зависит от другой. Запускаем их одновременно. И это будет всё ещё наш Workflow, потому что мы решили, какие задачи параллелить. LLM не принимает это решение. Но давайте будем усложнять. А что, если эту задачу нельзя разбить заранее? И клиент нам пишет: "Меня затопили соседи". И здесь нам уже надо будет динамически определять, какие подзадачи нам будут нужны для решения этой проблемы. И это будет подход с оркестратором и воркерами. Здесь у нас появляется LLM-оркестратор, который сам декомпозирует задачу. Клиент пишет в поддержку страховой: "Меня затопили соседи". И оркестратор разбивает их на подзадачи и передаёт уже воркерам. Воркер проверяет полис, другой находит ближайшего оценщика, третий генерирует черновик заявления. Собирает результат, и клиент получает готовый план действий, а не три отдельных ответа. Предположим, что наш бариста при заказе на большую команду. У нас один воркер собирает предпочтения, другой проверяет бюджет, третий ищет ближайшую доставку. А оркестратор сводит это всё в единый заказ. Но смотрите, здесь мы уже на границе. LLM уже принимает решение о декомпозиции. Но набор наших воркеров, он всё ещё предоставлен нами. И это будет гибрид. Давайте усложнять дальше. Что, если задача настолько открытая, что вы не можете предопределить ни шаги, ни воркеров, никакой Workflow здесь будет. И здесь к нам приходит на помощь React. И вот здесь в React Agent будет начинаться настоящая автономия. Наш бариста получает сообщение: "Организуй кофе-брейк для ретро, но у Марины сегодня день рождения". И агент сам решает: проверить предпочтения Марины, узнать, нет ли торта в меню, посмотреть бюджет, и если этот торт не влезает в бюджет, предложить альтернативу. Никто не прописывал эту цепочку заранее. Это примерно как когда ты говоришь своему Coding Agent: "Исправь баг". И дальше агент сам читает код, ищет причину, правит, тестирует. Принцип один: вы задаёте цель, агент строит план. И вот здесь вот у нас с вами появляется высокая стоимость, непредсказуемость и риски ошибок резко возрастают, потому что каждое решение принимает LLM, а не ваш код. Ну и давайте ещё немного усложним. А что будет, когда нашего одного агента не хватит? Нам с вами помогут Multi-Agent системы. И здесь у нас с вами несколько агентов работают параллельно. Один рефакторит, другой пишет тесты, третий обновляет документацию. Звучит это всё очень мощно. И мы с вами понимаем, что это намного больше вызовов модели, это намного больше токенов, выше стоимость и latency тоже растёт. А практика показывает интересную вещь: один агент с простыми инструментами часто эффективнее сложной мультиагентской системы. Посмотрите на Cloud Code. Grep, Bash, To-Do файлы в Markdown. Никаких векторных баз. И это прекрасно работает. Но есть один нюанс, потому что это в домене не программирования, где все инструменты дают довольно-таки точные результаты. И для кода это очень хорошо работает, потому что в этом домене у нас все инструменты дают точные результаты. Для задач, где нужна координация между несколькими неопределёнными источниками, тогда мультиагентский подход может быть необходим. Но по умолчанию начните с одного агента. А ещё лучше - стартануть с самого простого и дальше двигаться по усложнению. И поэтому, посмотрев на нашу иерархию, мы можем увидеть, что каждая ступень - это ответ на ограничение предыдущей. И каждая следующая ступень, она становится дороже с точки зрения разработки, сопровождения и стоимости вызова LLM. Поэтому мы с вами можем использовать одно простое правило: начнём с самого простого паттерна и будем усложнять по мере того, как мы решаем нашу задачу. И когда именно данные, а не интуиция нам доказали, что простого нам не хватает, тогда мы переходим к более сложным системам. Ладно, допустим, мы с вами выбрали. Что же дальше? Что внутри всего этого кроется? Давайте заглянем под капот. Неважно, какой паттерн: Workflow, Agent, мультиагентские системы. Под капотом каждого запроса происходит обработка через последовательность этапов. Или Pipeline. Это будет упорядоченная цепочка стадий. Фреймворки берут на себя только кусок этого ядра. Langchain Agent Executor - это Execution Loop. Crew AI - это оркестрация между агентами. Но кто валидирует вход? Кто проверяет инъекции? Кто собирает контекст из пяти источников в один промт? Кто фильтрует ответы на выходе? И это ваша ответственность. Фреймворки это часто не делают. И когда что-то сломается, а ведь мы знаем, оно всегда ломается, вы будете искать проблему именно здесь, в частях Pipeline, которые вы не написали. Но прежде чем мы нырнём в части нашего Pipeline, один компонент, который часто забывают - это системный промт. И это фундамент, на котором строится весь наш Pipeline. Не строчка текста, которую вы написали за 5 минут и забыли. Это архитектурный контракт поведения агента. По моему опыту, промт, которым вы владеете, даёт силу. Промт, спрятанный за абстракцией фреймворка, он её отнимает. И если агент дал плохой ответ, вы должны уметь открыть системный промт, увидеть точные инструкции и поправить их. Не перенастроить фреймворк, а поправить текст, который вы написали и понимаете. Поэтому версионируйте, ревьюйте и тестируйтесь. Относитесь к промтам, как к коду, потому что это и есть код вашего агента. Для нашего баристы System Prompt на экране. Обратите внимание на структуру. У нас есть четыре секции. Первая секция - роль и границы. Не просто "ты ассистент", а "что делаешь и что не делаешь". Без негативных границ агент начинает помогать за пределами своего домена. Отвечать на вопросы про погоду, политику, смысл жизни. Вам это сегодня не нужно. Вторая часть - правила. И они у нас с вами пронумерованы по приоритету. И это очень важно. Когда правила конфликтуют, они могут конфликтовать. Агент должен знать, что безопасность важнее бюджета, а бюджет важнее удобства. И без приоритетов LLM будет выбирать сам, и выберет он, скорее всего, не то, что вы хотели. Третья часть - это формат. Здесь мы описываем формат, который мы хотим получить. Без этого мы можем получить стену Markdown с заголовками или невалидный JSON или ещё что-то. И четвёртая часть - это пример. Для нашего баристы мы сюда положим один диалог. И это будет примером прямо в нашем системном промте. И это один из надёжнейших способов задать поведение. Модель видит не абстрактные правила, а конкретный образец. Такая структура: роль, приоритеты, формат, пример - работает не только для баристы, она универсальна. Вы можете сюда много чего добавить. Но лучше стартовать, как минимум, с этих четырёх частей. И это, это не настройка, это ближе к архитектурам. И поэтому мы должны управлять нашими архитектурами соответственно. Это может быть Git с код-ревью или, возможно, у нас есть специализированные системы управления промтами, вроде Langfuse, Prompt Layer или Human Loop, где можно версионировать, измерять эффективность, строить AB-тесты, откатываться к предыдущей версии. Главное - промт под контролем с историей изменений и метриками. И это не текстовый файл на рабочем столе. Так вот, System Prompt - это первый слой нашего с вами контекстного окна. Это фундамент. Но он не единственный. Каждый наш Stage Pipeline, который мы сейчас разберём, добавляет свои слои информации поверх этого фундамента. Так вот, к моменту, когда контекстное окно дойдёт до вызова LLM, оно у нас будет выглядеть как System Prompt. Потом у нас с вами пойдут слой за слоем: знания, память, инструменты и в самом конце - запрос пользователя. И Pipeline, о котором мы будем говорить - это конвейер, который собирает это контекстное окно. И каждый Stage отвечает за свой слой. Давайте пройдём этот конвейер целиком. Одно небольшое уточнение. То, что я вам покажу дальше - это не стандарт из учебника, это моя синтезированная модель. Я собрал её из гайдов Anthropic, OpenAI, Google, из реальных продакшн систем, из разбора инцидентов и построения множества агентов. Мы разберём много Stage. У вас может быть меньше, а может быть и больше. И это нормально. Большинство проектов стартуют с четырёх-пяти и растут по мере необходимости. Но сначала критическое различие. Pipeline работает по-разному для Workflow и для агента. Workflow Pipeline в основном линейный. Запрос входит, проходит Stage от начала до конца. Но есть важный нюанс: отдельные Stage могут содержать мини-циклы. Как пример: Security проверил ответ, нашёл PII и вернул обратно модели на переформулировку. Или Post-processing распарсил JSON, и он оказался невалидным. Retry. И это будет всё ещё Workflow. Вы, разработчики, определили, когда и куда возвращаться. Путь предопределён. И отличие от агентов в том, что решение о возврате принимает ваш код, а не LLM. А Agent Pipeline содержит цикл. LLM решает, нужен ли Tool Call. Если да, то вызов инструмента, результат возвращается. И часть Pipeline проходится снова. И это будет у нас Agent Loop. Мы разберём его отдельно через несколько минут. Но структура Stage общая. Логика нашего Pipeline может быть объединена одной фразой: "Блокируй рано, трать поздно". Дешёвые проверки первыми, а дорогой LLM вызов - последним. Давайте проведём один реальный запрос через весь Pipeline, чтобы вы увидели, зачем нужен каждый Stage. Пользователь пишет баристе: "Хочу кофе". Итак, с чего же нам с вами начать? И начнём мы с вами с Validation. И здесь мы с вами будем экономить деньги. Мы проверяем: входные данные корректны? Не пустая ли это строка? Не бинарный ли это мусор? А может быть, это неподдерживаемый нами язык? Если нет, всё, стоп. Ноль центов потрачено. Звучит очень примитивно. Но посчитайте: если ваш Customer Support Agent получает миллион запросов в месяц, 5% - это будет мусор: пустые строки, случайные нажатия, может быть, бот-трафик. Без валидации эти 50.000 запросов проходят весь Pipeline: рак, LLM, Post-processing. По 5 центов каждый. 2.500 долларов на мусор. Один if с Regex, и эти 2.500 остаются у вас. Вот такой интересный ROI для фазы валидации. Итак, наш запрос "Хочу кофе", конечно, проходит валидацию. Он абсолютно корректен. Но корректный не значит безопасный. И следующий Stage у нас будет Security. И это будет безопасность на входе. Здесь мы будем проверять: нет ли в запросе Prompt Injection? Не пытается ли кто-то заставить агента выдать системный промт или выполнить несанкционированные действия? Проверка стоит доли цента. А если бы мы пропустили инъекцию и дошли до рак + LLM, потратили бы уже 10 центов. И, возможно, при этом слили конфиденциальные данные или сделали какие-то действия, которые наш агент точно не должен делать. Поэтому Security до дорогих операций. Это не паранойя, это экономика. И наш запрос "Хочу кофе" успешно проходит Input Security. Но посмотрев на этот запрос подробно, мы поймём, что в нём очень мало информации. И следующая фаза - обогащение запроса контекстом. И эта фаза очень сильно зависит от нашего домена и то, как мы можем изменить этот запрос. Для нашего агента-баристы, пускай он сходит в чат и посмотрит, что же в нём находится. И видит сообщение: "Через час ретро!" И если мы с вами это объединим, получится: "Пользователь хочет кофе, через час у команды ретро". И два слова превратились в задачу с контекстом. Без этого шага наш бариста предложил бы просто чёрный кофе. С этим же шагом он может понять, что надо подготовить заказ для команды перед встречей. И контекст меняет всё. Но для правильного заказа нам нужны знания. И здесь будет следующая фаза. Наш запрос обогащён, но нам надо понять, что мы знаем. У нас может быть здесь Memory Retrieval: что мы помним об этом пользователе? Его предпочтения. Алексей пьёт капучино на овсяном, Марина - латте на миндальном. Также, возможно, история: в прошлый раз заказывали маффины, и они понравились. Без памяти же каждый разговор начинается с нуля. С памятью агент узнаёт вас. И в этом Stage часть у нас будет про нашего пользователя. И это про память. И наша Intelligence Zone будет состоять из нескольких шагов. Как мы видим, первая будет про память о пользователе. Вторая же будет про предметную область. И здесь мы с вами ищем в нашей базе знаний: меню кофейни, текущие акции, ограничения команды. Customer Support - это Stage у нас будет искать по часто задаваемым вопросам, по документации. Code Agents - по кодовой базе. Для DevOps - это ранбуки. Stage один и тот же, но данные в нём будут абсолютно разные. И тут есть момент, который многие пропускают. Наш рак вернул документы. Но откуда вы знаете, что они чистые? И с этим нам поможет следующий Stage. Content Filtering - проверка рак-результатов. Не вернулись ли битые документы? Нет ли в результатах инъекций через данные? Для большинства проектов это проверка на пустые результаты. Для тех, где очень важна безопасность окружений - это полноценная фильтрация. В третьем видео нашей серии мы подробно разберём эту часть. Ну, мы проверили наш рак, у нас всё хорошо, мы можем двигаться дальше. Что же будет следующим? Следующее у нас будет также довольно-таки большая зона, в которой мы будем оптимизировать. Это будет Preparation Zone. И здесь на входе у нас с вами есть обогащённый запрос, память о пользователе, документы из рак. И всё это нам надо собрать в один промт. Как мы помним, System Prompt - фундамент. Поверх него пойдут наши рак-документы, память, и только потом запрос пользователя. Каждый кусок нашего промта на своём месте. Но есть ещё одно измерение - это история чата. Если это не первое сообщение, а десятое, предыдущие 10 тоже должны быть в контексте. Иначе агент теряет нить разговора. Но мы знаем, что контекстное окно у нас ограничено, и каждый токен стоит денег. И у нас должен быть бюджет для токенов. И это задача со множеством переменных: текущие запросы, рак-документы, память, история. И это всё должно влезть. А если не влезает, что же нам делать? Мы можем порезать историю на текущий запрос. И здесь есть несколько стратегий: Sliding Window - это мы оставляем последние N сообщений. Старые просто выбрасываем. Либо Summarization - мы сжимаем старую историю в краткое резюме. Или Compaction, как это делает Cloud Code, где при переполнении контекста вся история автоматически уплотняется. Подробно об этом будем говорить во второй серии наших видео. Итак, контекст у нас с вами собран. Но какую модель нам надо с вами выбрать? Здесь как раз может присутствовать наш Smart Routing. "Хочу кофе" - это простой запрос, хватит и дешёвой модели. "Организуй кофе-брейк на 20 человек с учётом аллергии и бюджета" - это уже сложный, и, скорее всего, нужна будет большая, дорогая модель. И наша маленькая модель-классификатор решает за миллисекунды, а экономия будет огромна. Но нам важно не просто выбрать модель. Если эта модель может быть запущена в двух режимах: с reasoning'ом и без, нам надо будет определить: нужен ли нам этот Thinking Mode? Или нам хватит простого запроса? Теперь мы с вами готовы выполнить этот запрос. И мы приходим к нашей следующей большой зоне, в которой мы тратим уже наши доллары. Ну, конечно, здесь будет фаза генерации. И это сам LLM-вызов. И тут может происходить вот это ключевое отличие от Workflow до агента. Workflow - один вызов, результат идёт дальше. Агент у нас фаза генерации может содержать цикл. LLM вызвал Tool, получил результат, потом снова LLM, потом снова Tool. И так, пока не решит ответить. Это упрощённая схема. В реальном продакшн сюда добавляются проверки лимитов, обработка ошибок, валидация вызовов, логирование. Но костяк примерно вот так вот и будет выглядеть. Так работает подавляющее большинство агентских систем. И вот здесь есть проблема. Этот цикл беззащитен. Бомба с часовым механизмом. Давайте разберём, как именно она может взорваться. И первая группа проблем будет - потеря контроля. Агент не останавливается, когда должен, и продолжает крутить этот цикл. Такан, агент выдал один и тот же результат 58 раз подряд. Не два, не пять, 58. Игнорировал команды на остановку. Задача давно уже решена, а он продолжал крутиться. То ли он не понял, что пора останавливаться, то ли решил: "Проверю-ка я ещё раз, что всё верно". А представьте это на тысячах пользователей одновременно. Следующая группа - это деньги. Каждая итерация - это вызов модели, это оплата. 10 итераций по центу - 10 центов. Это нормально. 100 итераций - это уже доллар. Возможно, это терпимо. Но помните кейс из начала: прототип за 50 долларов масштабировался до 2,5 млн в месяц. Также и второй: прототип за 500 долларов вырос до 847.000. Это в 700 раз. И помните из нашего прошлого блока: контекст растёт на каждой итерации, а вы платите за весь контекст при каждом вызове. И третья группа - корректность. LLM часто галлюцинирует. Все мы это с вами уже прекрасно на себе почувствовали. И в цикле это опаснее всего, потому что галлюцинация на шаге три, она становится фактом для шага четыре. Но на шаге пять это уже становится основой для принятия решения. И здесь у нас может быть несколько типов таких ошибок. И первый - это неправильные параметры. Агент вызывает Tool с неверными данными. Количество чашек кофе 999 вместо одной. Или как в Data Talk Club: Terraform Destroy вместо точечного удаления. И следующий - это фантомные вызовы. LLM говорит: "Я проверил базу данных и нашёл три результата". Но вызова инструмента не было совершено. Результат выдуман целиком. И это классическая проблема галлюцинации инструментов. И вероятность нашего успеха падает с каждым шагом. И поэтому нам надо добавлять защитные ограничения на такие циклы для того, чтобы не попасть в неприятную ситуацию. Что же это за ограничители? И первое - это лимит на количество итераций. И он нам говорит, сколько кругов может сделать наш цикл. Для Code Agent 25 - это нормально. Там задачи у нас очень длинные. Для Customer Support - 5. Дальше уже давайте-ка передавать человеку, чтобы понять, что же идёт не так. Для баристы тоже, возможно, 5. Это надо всё тестировать и смотреть, за сколько итераций он достигает успеха. Следующее - это бюджет токенов. Сколько можно суммарно потратить за все наши циклы. Превысил - стоп. И неважно, на какой ты итерации. И следующее - это лимит на инструменты. Сколько раз можно дёрнуть один и тот же Tool. Как пример, наш агент-бариста хочет понять, какая температура, потому что это может повлиять на типы напитков. И он вызывает её уже четвёртый раз подряд. И это странно. Поэтому мы говорим ему: "Стоп, хватит узнавать погоду. Она не изменилась за последние 3 секунды". Но надо иметь в виду, что для каждой задачи значения этих лимитов надо подбирать самостоятельно, итеративно, смотреть, что нам хватает, а чего не хватает. Поэтому ставьте метрики и наблюдайте за вашей системой. И главное - это жёсткие ограничения в коде, не в промте. Написали в промте: "Пожалуйста, остановись после 10 шагов". Это рекомендация. Модель может послушать, а может и не послушать. Поэтому контролируйте это именно в коде. Не отдавайте контроль этих лимитов на уровень модели. Вы можете сюда добавить и другие лимиты. Главное - относиться к ним, как к бюджетному контролю, как к SLO для сервисов. Сколько стоит один принятый результат? Агент потратил доллар и решил задачу. Отлично. Потратил доллар и не решил - значит, мы с вами выбросили деньги. Четвёртый ограничитель - это подтверждение человеком. Human in the Loop. Первые три срабатывают при превышении лимитов. А этот срабатывает при опасности. Возможно, мы хотим совершить какие-то необратимые действия: разместить заказ, отправить платёж, удалить данные. И это только через подтверждение человека. Следующее - это аномальные параметры. Допустим, количество заказа превышает типичное в пять раз. Всё, пауза, передаём человеку. Или сумма заказа больше дневного бюджета. Пауза, остановились. А может быть, кто-то заказал у нашего баристы 500 эспрессо? И это для конференции или наш агент сошёл с ума? Надо проверить. И это реализуется прямо внутри цикла. Перед выполнением вызова инструмента проверяем уровень риска и параметры. Если надо, ставим цикл на паузу и запрашиваем подтверждение человека. Многие фреймворки это уже поддерживают из коробки. Но принцип не зависит от фреймворка. И теперь очень интересный момент, который часто не видим, когда вы только начинаете создавать агентские системы. Что вы говорите модели, когда ограничитель сработал? Или, возможно, наш Tool вернул какую-то ошибку. Если вы ему просто отправите: "Ошибка, лимит достигнут". Модель не понимает, что случилось. Это как сказать человеку: "Ошибка" без объяснения. И что человек сделает? Конечно, попробует сделать это ещё раз. Если же вы модели скажете: "Инструмент Get Weather вызван четыре раза, максимум при этом всего три. У тебя достаточно данных. Дай финальный ответ прямо сейчас". Модель понимает ограничения и адаптируется. Здесь у нас присутствует конкретика: контекст и инструкция. И последнее: что делать, если агент остановлен? У нас есть несколько стратегий. Первая - это частичный результат. Мы можем вернуть пользователю, допустим, как наш бариста: "Я нашёл предпочтения трёх человек из 10, вот они. Остальные уточните сами". И пользователь решает, достаточно ли. Следующее - это эскалация. Задача сложнее, чем я могу решить автоматически. Передаю оператору. И это очень хорошо работает в Customer Support системах. И следующее - это повтор с другими параметрами. Другая модель, упрощённый запрос, урезанный контекст. Помните, что в продакшн нам надо сделать так, чтобы наш пользователь не получал пустоту. Так вот, если цикл - это наше сердце, то что же будет нашими руками? И это инструмент. Агент без инструментов - это чат-бот. Дорогой, галлюцинирующий чат-бот. Инструменты - это руки агента. И вот что важно понять: проектирование инструментов часто важнее, чем просто выбор модели. Можно взять лучшую модель в мире, но если инструменты спроектированы плохо, агент будет ошибаться. И Anthropic пишет об этом: критически важно проектировать набор инструментов и их документацию ясно и продуманно. А вот ещё немного информации. Shopify, доклад на ICML. Их агент Sidekick. Когда инструментов было до 20, всё управляемо. От 20 до 50 - границы размывались. Комбинации инструментов давали неожиданные результаты. Больше 50 - они назвали это "Смерть от тысячи инструкций". Невозможно запихнуть описание всех инструментов в системный промт. Модель просто тонет. Но до масштаба Shopify надо ещё дорасти. А вот правильное описание инструмента нужно с первого дня. Как модель выбирает инструмент? Она читает его описание. Его имя, схема параметров. И на основе этого решает: подходит он или нет? Невнятное имя, и модель выберет не тот инструмент или пропустит нужный. Следующее - это описание. Мы с вами привыкли писать документацию для людей, а описание инструментов у нас читает модель, не человек. Ей нужны какие вещи? Что инструмент делает, когда его вызывать, и какие условия должны быть выполнены до вызова. Вызывай после подтверждения человека. Одна строчка, которая предотвращает целый класс ошибок. И важный нюанс: исследования показывают, что модель лучше реагирует на позитивные инструкции. Сначала проверь бюджет через Get Budget - работает надёжнее, чем "Не вызывай без проверки бюджета". Говорите модели, что делать, а не что не делать. Следующее - это параметры. Здесь чаще всего у нас будет с вами JSON. Здесь мы с вами обозначим тип, границы, enum. И чем строже схема, тем меньше модель будет галлюцинировать. Также часто мы можем передать значения по умолчанию для необязательных параметров. Если пользователь не сказал срочно, то приоритет автоматически поставим Normal, а не придуманной моделью. Следующая часть - это ответ. Здесь будет структурированный JSON. Чаще всего. Конечно, от вашей модели будет зависеть описание Tool. И модели надо будет разобрать результат вызова и принять своё решение: подходит это, надо дальше совершать другие вызовы или у нас уже есть все нужные нам данные. Следующая часть - это ошибки. И это очень важно. Здесь будет крыться разница между хорошим и плохим инструментом. Наша любимая ошибка: "Something went wrong", и модель у нас будет с вами в тупике. Она не знает, что случилось и что делать. Как пример: "Бюджет превышен, и текущая сумма 4.500. Лимит же у нас 4.000. Предложение - уменьшить заказ". Модель видит конкретику и предлагает решение пользователю. Так вот, ошибка - это не конец, это инструкция для следующего шага. И это очень важно понимать, потому что наши с вами бэкенды часто дают такие ошибки, которые не просто являются не инструкциями, они и нас с вами запутывают. Они всех запутывают. Так вот, запутать модель - это значит просто так сжечь бюджет. Да, ошибки не относятся к описанию наших Tool. Они относятся непосредственно к нашим Tool. Поэтому с ними надо будет очень хорошо и качественно поработать. Но об этом мы ещё сегодня поговорим. Итак, мы с вами спроектировали наши инструменты. Но как их подключать? Здесь в индустрии пришла к стандарту MCP. Model Context Protocol. Подробно разбирать протокол не будем. По нему у меня есть видео. Правда, с тех пор протокол поменялся, как и всё за последний год, очень сильно. Так что сейчас это будет размытием нашего фокуса. Но один архитектурный момент разобрать мы обязаны, потому что именно он как раз-таки ломает всю работу. Сейчас появилось множество инструментов, которые автоматически оборачивают наши с вами бэкенды, базы данных, API в MCP-серверы, которые очень легко подключать к нашим агентам. Звучит это всё очень красиво. Подключил и поехал. Многие именно так и делают: фигак, фигак в продакшн. А потом бэкенд, что делает? Возвращает нашу с вами любимую ошибку, которую мы с вами только что обсуждали: "Something went wrong". Или тайм-аут, или невалидный ответ, или частичные результаты. И если вы не продумали каждый из этих сценариев, значит, вы не подключили инструмент к вашему агенту. Правило простое: прежде чем обернуть сервис в MCP, пройдитесь по всем ошибкам, которые он может вернуть. Для каждой сделайте ответ, который модель поймёт. С конкретикой: что случилось, можно ли повторить, что делать вместо этого. Все те же самые правила, которые мы разбирали для наших инструментов.