
Artificial intelligence has transformed text to speech ai technology from robotic, monotone voices into remarkably human-like speech synthesis that’s revolutionizing how we interact with digital content. Modern ai text to speech systems leverage advanced neural networks to produce natural-sounding voices that can convey emotion, adjust pacing, and even replicate specific speaking styles. This breakthrough has opened unprecedented opportunities for accessibility, enabling visually impaired users to consume written content effortlessly, while simultaneously boosting productivity for professionals who need to multitask or absorb information on the go.
The applications span far beyond basic accessibility features. From creating engaging audiobooks and podcasts to powering virtual assistants and educational platforms, text to voice ai technology is reshaping industries and improving user experiences across countless digital touchpoints. Whether you’re a content creator seeking to expand your audience reach, a business looking to enhance customer interactions, or simply someone curious about the latest advances in ai voice synthesis, understanding this technology has become essential.
This comprehensive guide will walk you through everything you need to know about neural text to speech technology, from the underlying mechanics and key capabilities to practical applications and selection criteria for choosing the perfect solution for your specific needs.
What is AI Text to Speech Technology?
AI text to speech technology represents a revolutionary advancement in converting written text into natural-sounding human speech using artificial intelligence algorithms. Unlike traditional text-to-voice systems that relied on concatenative synthesis and robotic-sounding output, modern text to speech ai leverages deep learning neural networks to produce remarkably lifelike vocal performances that closely mimic human intonation, emotion, and speaking patterns.
At its core, ai text to speech technology analyzes written content and transforms it into audio output by understanding linguistic context, pronunciation rules, and prosodic elements like rhythm and stress. This process involves multiple sophisticated layers of machine learning that work together to create seamless voice synthesis that can adapt to different speaking styles, languages, and even emotional tones.
Core Technology and Neural Networks
The foundation of modern text to voice ai systems rests on advanced neural network architectures, particularly deep learning models that have transformed the quality and naturalness of synthesized speech. These systems typically employ sequence-to-sequence models, such as Tacotron and WaveNet, which learn complex patterns from vast datasets of human speech recordings.
Neural text to speech models operate through multiple processing stages. The first stage involves text analysis, where the system breaks down written content into phonemes, syllables, and linguistic features. The second stage uses encoder-decoder architectures to convert this textual representation into mel-spectrograms, which capture the acoustic properties of speech. Finally, vocoder networks transform these spectrograms into high-quality audio waveforms that sound remarkably human.
These neural networks excel at capturing subtle nuances in human speech, including natural pauses, emphasis patterns, and contextual pronunciation variations. Advanced models can even generate speech with specific emotional characteristics, making them invaluable for applications ranging from audiobook narration to interactive voice assistants.
Evolution from Traditional TTS Systems
Traditional text-to-speech systems relied heavily on concatenative synthesis, which stitched together pre-recorded speech segments from human speakers. While functional, these legacy systems produced choppy, robotic-sounding output with unnatural transitions between words and limited flexibility in voice characteristics.
The transition to ai voice synthesis marked a paradigm shift in speech technology. Where older systems required extensive manual tuning and phonetic databases, modern AI approaches learn directly from raw audio data, automatically discovering optimal speech patterns and pronunciation rules. This evolution has dramatically reduced the time and resources needed to create new synthetic voices while simultaneously improving output quality.
Contemporary AI systems also offer unprecedented customization options. Users can now generate speech in multiple languages, adjust speaking rates and emotional tones, and even create custom voice profiles that match specific requirements. This flexibility has opened new possibilities for accessibility applications, content creation, and personalized user experiences.
Key Components of Modern AI TTS
Modern ai text to speech systems integrate several critical components that work in harmony to produce high-quality voice output. The text analysis module serves as the foundation, performing linguistic preprocessing including normalization, tokenization, and phonetic transcription. This component ensures that abbreviations, numbers, and special characters are correctly interpreted and pronounced.
The acoustic modeling component represents the heart of neural voice synthesis, utilizing deep learning architectures to predict acoustic features from linguistic inputs. These models learn complex relationships between text and speech, enabling them to generate natural prosody and intonation patterns that make synthesized speech sound authentically human.
The final component involves the audio generation module, typically implemented through neural vocoders that convert acoustic predictions into high-fidelity audio waveforms. Advanced vocoders can produce speech at various sample rates and bit depths, ensuring compatibility with different playback systems and quality requirements.
Quality control mechanisms also play a crucial role, continuously monitoring output for consistency and naturalness. These systems can detect and correct pronunciation errors, adjust speaking pace for optimal comprehension, and maintain consistent voice characteristics throughout longer passages of text.
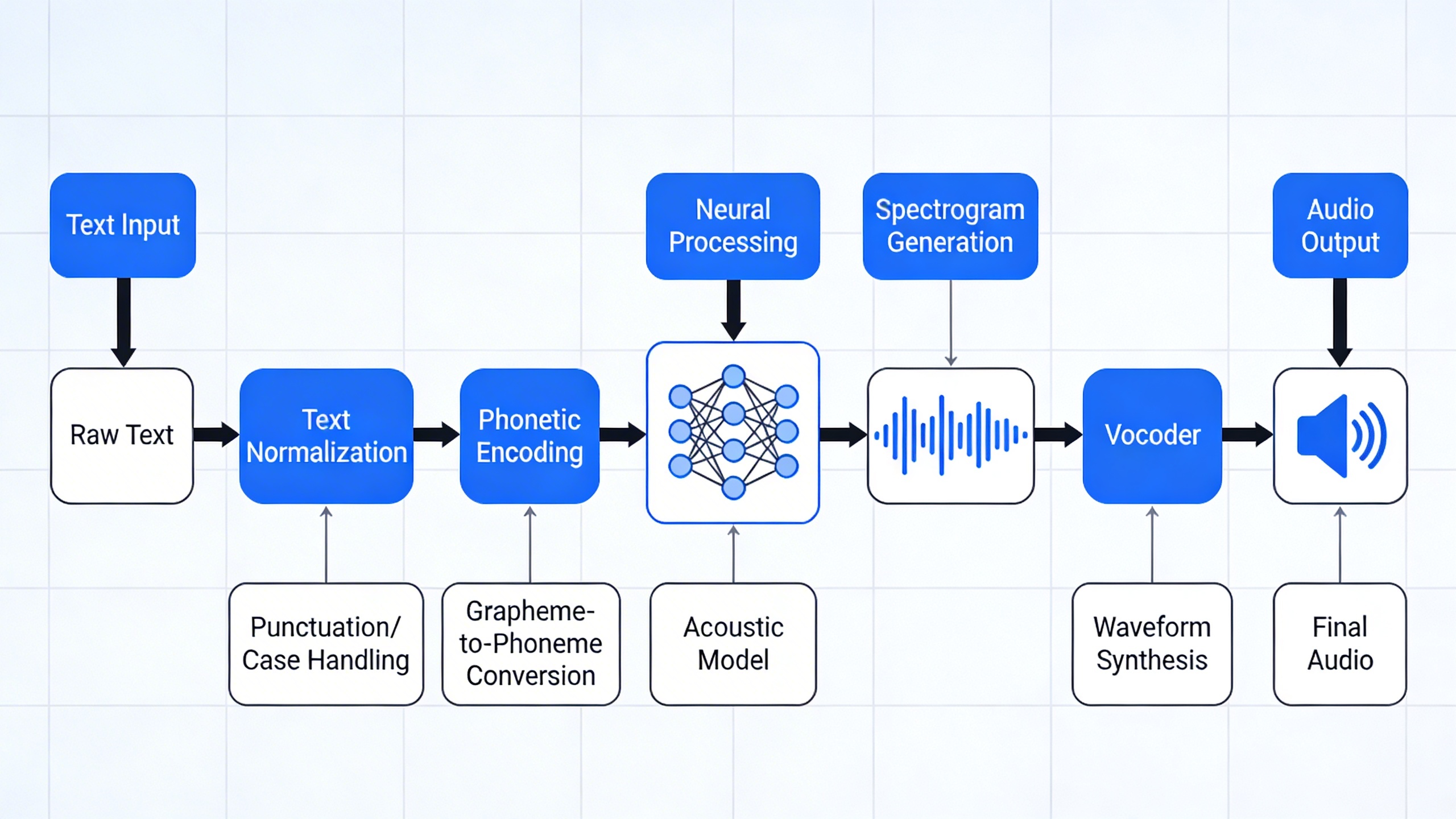
How AI Text to Speech Works
Understanding how text to speech ai operates requires examining the sophisticated pipeline that transforms written words into natural-sounding speech. Modern ai text to speech systems leverage multiple interconnected processes, each contributing to the final audio output that mimics human vocal patterns and intonation.
Natural Language Processing Pipeline
The journey from text to voice begins with comprehensive text analysis and preprocessing. When you input text into an ai voice synthesis system, the first step involves parsing the content to understand context, punctuation, and linguistic structure. The system identifies sentence boundaries, analyzes grammatical components, and determines appropriate emphasis patterns based on syntax.
During preprocessing, the text undergoes normalization where abbreviations expand into full words, numbers convert to their spoken equivalents, and special characters receive proper pronunciation guidance. For example, “Dr. Smith’s 5th appointment at 3:30 PM” becomes “Doctor Smith’s fifth appointment at three thirty P M.” This crucial step ensures the neural text to speech engine receives properly formatted input for accurate voice generation.
The system also performs linguistic analysis to understand context clues that influence pronunciation. Homographs like “read” require contextual understanding to determine whether the past or present tense pronunciation applies. Advanced text to voice ai systems maintain extensive linguistic databases that help resolve these ambiguities automatically.
Voice Synthesis and Audio Generation
Once text preprocessing completes, the system generates phonemes—the smallest units of sound that distinguish words from each other. The ai text to speech engine maps each word to its corresponding phonetic representation using sophisticated algorithms that consider regional pronunciation variations and speaking patterns.
Modern neural networks then process these phonemes through multiple layers that determine prosodic features including pitch, rhythm, stress, and intonation. The system calculates optimal timing for each sound unit, ensuring natural-sounding speech patterns that avoid the robotic qualities associated with earlier synthesis technologies.
Audio waveform creation represents the final transformation stage where digital signals convert into audible sound waves. The ai voice synthesis process generates thousands of audio samples per second, carefully modulating frequency and amplitude to produce clear, intelligible speech. Advanced systems can adjust speaking rate, add emotional inflection, and even simulate breathing patterns for enhanced realism.
Machine Learning Training Process
The sophistication of modern text to voice ai stems from extensive machine learning training using vast datasets of human speech recordings. Training datasets typically contain hundreds of hours of high-quality audio paired with corresponding text transcriptions, allowing neural networks to learn complex relationships between written language and vocal expression.
During training, algorithms analyze countless examples of how professional speakers pronounce words, handle punctuation, and convey meaning through vocal variation. The system learns to replicate subtle nuances like the slight pause before important information or the rising intonation that signals a question.
Neural text to speech models undergo iterative refinement through techniques like transfer learning, where pre-trained models adapt to new voices or languages more efficiently. This approach enables rapid development of voice models that maintain consistency while offering distinct personality characteristics.
The training process also incorporates feedback mechanisms that continuously improve output quality. By analyzing user interactions and comparing generated speech against human benchmarks, these systems evolve to produce increasingly natural and expressive voice synthesis results.

Key Features and Capabilities
Modern AI text to speech systems have evolved far beyond robotic-sounding computer voices. Today’s neural text to speech platforms deliver sophisticated capabilities that make synthetic speech nearly indistinguishable from human conversation. Understanding these key features helps you choose the right solution for your specific needs.
Voice Quality and Naturalness
The hallmark of advanced text to speech ai technology lies in its ability to produce human-like speech that flows naturally. Contemporary systems utilize deep learning models trained on vast datasets of human speech patterns, enabling them to capture subtle nuances like breathing patterns, vocal fry, and natural pauses that make conversations feel authentic.
Neural networks analyze not just individual words but entire sentences to understand context and adjust pronunciation accordingly. This contextual awareness allows ai text to speech systems to handle homographs correctly—words spelled the same but pronounced differently based on meaning. For example, the word “lead” will be pronounced differently in “lead the team” versus “lead pipe.”
Emotional expression represents another breakthrough in voice quality. Advanced platforms can modify tone, pace, and inflection to convey specific emotions like excitement, concern, or empathy. This capability proves particularly valuable for audiobook narration, customer service applications, and educational content where emotional engagement enhances the listening experience.
Multi-Language and Accent Support
Global accessibility drives the development of comprehensive language support in text to voice ai systems. Leading platforms now offer synthesis capabilities across dozens of languages, from widely spoken options like English, Spanish, and Mandarin to less common languages like Welsh or Swahili.
Regional accent variation adds another layer of sophistication. Users can select from multiple accent options within a single language—choosing between British, American, Australian, or Indian English accents, for instance. This granular control ensures that synthesized speech matches the intended audience’s linguistic preferences and cultural expectations.
Cross-language pronunciation handling has also improved significantly. Modern ai voice synthesis systems can correctly pronounce foreign words and names within different language contexts, maintaining the original pronunciation while seamlessly integrating with the primary language flow.
Customization and Voice Cloning
Personalization capabilities in neural text to speech technology extend far beyond basic voice selection. Users can adjust speaking rate, pitch, volume, and emphasis patterns to create unique vocal characteristics that align with brand identity or personal preferences.
Voice cloning represents the cutting edge of customization, allowing users to create synthetic versions of specific human voices. This technology requires only a few minutes of sample audio to generate a digital voice model that maintains the original speaker’s distinctive characteristics. Applications range from preserving the voices of loved ones to creating consistent brand voices for marketing campaigns.
Professional voice customization tools enable fine-tuning of prosodic elements—the rhythm, stress, and intonation patterns that give speech its natural flow. Content creators can adjust these parameters to match specific contexts, whether creating authoritative narration for documentaries or friendly tones for children’s content.
Real-time voice modification adds dynamic flexibility to text to speech ai applications. Users can adjust vocal characteristics on the fly, switching between different emotional states or speaking styles within a single session. This capability proves especially useful for interactive applications like virtual assistants or gaming characters that need to respond appropriately to changing contexts.
SSML (Speech Synthesis Markup Language) support provides advanced users with granular control over speech output. This markup language allows precise specification of pronunciation, pauses, emphasis, and other vocal elements, enabling professional-grade audio production directly from text input.

Applications and Use Cases
The versatility of text to speech ai technology has led to its adoption across numerous industries and applications. From breaking down accessibility barriers to revolutionizing content creation workflows, neural text to speech systems are transforming how we interact with digital information. Understanding these practical applications helps organizations and individuals identify opportunities to leverage this powerful technology.
Accessibility and Assistive Technology
One of the most impactful applications of ai text to speech technology lies in accessibility support, particularly for individuals with visual impairments or reading disabilities. Screen readers powered by advanced ai voice synthesis can convert web content, documents, and digital interfaces into natural-sounding speech, enabling users to navigate digital environments independently.
Modern accessibility tools go beyond basic text reading. They can interpret complex document structures, describe image content when alt-text is available, and even adjust speech patterns based on content type. For instance, when reading mathematical equations or code snippets, the system can modify its delivery to enhance comprehension.
Educational institutions increasingly rely on text to voice ai solutions to support students with dyslexia, ADHD, or other learning differences. These tools can read textbooks aloud, provide audio feedback on written assignments, and help students process information through their preferred learning modality. The technology also benefits elderly users who may experience declining vision or cognitive changes that make traditional reading challenging.
Content Creation and Media Production
The content creation industry has embraced ai text to speech technology as a game-changing tool for producing audio and video content at scale. Podcast creators use neural text to speech systems to generate intro segments, advertisement reads, or even entire episodes when human narration isn’t feasible. This approach significantly reduces production time and costs while maintaining consistent audio quality.
Video production teams leverage ai voice synthesis for creating voiceovers in multiple languages, enabling global content distribution without hiring voice actors for each target market. YouTube creators and online course developers particularly benefit from this capability, as they can produce multilingual versions of their content efficiently.
The technology also serves audiobook production, where publishers can quickly convert written works into spoken format. While human narrators remain preferred for premium productions, text to voice ai provides an economical solution for educational materials, technical documentation, and niche publications where traditional narration costs would be prohibitive.
News organizations and content agencies use automated voice synthesis to create audio versions of written articles, expanding their reach to commuters and multitasking audiences who prefer audio consumption. This application has become particularly valuable as audio content consumption continues to grow across demographics.
Business and Educational Applications
In corporate environments, ai text to speech technology streamlines communication and training processes. Human resources departments use voice synthesis to create consistent training materials that can be easily updated and distributed across global teams. The technology ensures uniform message delivery regardless of trainer availability or geographic constraints.
Customer service operations have integrated text to speech ai into their workflows to handle routine inquiries and provide 24/7 support. Interactive voice response systems powered by neural text to speech can deliver personalized information, read account details, or guide customers through complex processes with natural-sounding speech that reduces caller frustration.
E-learning platforms represent one of the fastest-growing applications for ai voice synthesis technology. Educational content creators can transform written course materials into engaging audio lessons, making learning more accessible to auditory learners and enabling students to consume content while commuting or exercising. The technology also supports language learning applications by providing consistent pronunciation examples and conversational practice scenarios.
Corporate communications benefit from text to voice ai through automated announcement systems, training video production, and internal podcast creation. Marketing teams use the technology to create audio advertisements, social media content, and promotional materials that maintain brand voice consistency across campaigns.
Healthcare organizations employ voice synthesis for patient education materials, medication instructions, and appointment reminders. The technology ensures critical health information is delivered clearly and consistently, reducing miscommunication risks that could impact patient outcomes.
Benefits of AI Text to Speech
The adoption of text to speech AI technology delivers transformative advantages across multiple dimensions, from democratizing content access to revolutionizing how organizations produce and distribute audio materials. These benefits extend far beyond simple convenience, creating meaningful impact for individuals, businesses, and entire communities.
Enhanced Accessibility and Inclusion
AI text to speech serves as a powerful equalizer, breaking down barriers that traditionally limit content access. Individuals with visual impairments, dyslexia, or reading difficulties can now consume written materials through high-quality synthetic speech that rivals human narration. This technology transforms educational resources, workplace documents, and digital content into accessible formats without requiring specialized preparation.
The universal design principles embedded in modern text to voice ai systems extend beyond disability accommodation. Elderly users experiencing age-related vision changes, individuals learning new languages, and people with temporary injuries all benefit from audio alternatives to text-based information. Neural text to speech technology has reached a sophistication level where synthetic voices convey emotional nuance and contextual meaning, making content consumption genuinely engaging rather than merely functional.
Productivity and Efficiency Gains
Modern professionals leverage ai voice synthesis to transform their workflow patterns and maximize productive time. The multitasking capabilities enabled by text to speech AI allow users to absorb information while commuting, exercising, or performing routine tasks. This parallel processing approach effectively expands available learning and consumption hours throughout the day.
Content creators and educators experience dramatic efficiency improvements when converting written materials into audio formats. What previously required professional recording sessions, multiple takes, and extensive editing can now be accomplished in minutes through advanced ai text to speech platforms. The technology handles pronunciation consistency, maintains steady pacing, and eliminates the fatigue factors that affect human narrators during lengthy recording sessions.
Organizations implementing text to voice ai for internal communications report significant time savings in training delivery, policy updates, and knowledge sharing initiatives. Teams can consume important information during travel time or while multitasking, leading to better information retention and faster decision-making processes.
Cost-Effective Content Distribution
The economic advantages of neural text to speech become particularly evident when scaling audio content production. Traditional audiobook creation, podcast development, and multimedia training materials require substantial investments in professional voice talent, studio time, and post-production services. AI voice synthesis eliminates these recurring costs while maintaining consistent quality standards.
Educational institutions and corporate training departments achieve remarkable cost reductions by converting existing written curricula into audio formats using text to speech ai technology. The ability to update content instantly without re-recording entire modules provides ongoing value that compounds over time. Marketing teams can rapidly prototype audio advertisements, test different voice characteristics, and iterate on messaging without budget constraints typically associated with professional voice work.
Global organizations particularly benefit from the multilingual capabilities of advanced ai text to speech systems, which can generate consistent brand voices across different languages and regions without maintaining separate voice talent contracts in each market. This scalability enables rapid international expansion while maintaining audio content quality standards.
Choosing the Right AI Text to Speech Solution
Selecting the optimal text to speech ai platform requires careful evaluation of multiple factors that align with your specific use case and technical requirements. The market offers numerous solutions ranging from simple conversion tools to sophisticated neural text to speech engines, each with distinct advantages and limitations.
Evaluation Criteria and Quality Metrics
Voice quality stands as the primary consideration when evaluating ai text to speech solutions. Listen for naturalness in speech patterns, proper pronunciation of complex terms, and emotional expressiveness. High-quality ai voice synthesis should produce speech that flows smoothly without robotic artifacts or unnatural pauses between words.
Assess pronunciation accuracy across different languages and technical terminology relevant to your content. Test the system with challenging text samples including numbers, abbreviations, and industry-specific jargon. The best text to voice ai platforms maintain consistent quality across diverse content types while offering customization options for specialized vocabulary.
Consider the range of available voices, including gender options, age variations, and accent diversity. Premium solutions typically provide dozens of voice options with the ability to adjust speaking rate, pitch, and emphasis. Evaluate whether the platform supports SSML (Speech Synthesis Markup Language) for fine-tuning pronunciation and delivery style.
Free vs Premium Options
Free ai text to speech services often impose significant limitations including restricted character counts, limited voice selections, and basic audio quality. These solutions work well for testing purposes or light personal use but may not meet professional standards for commercial applications.
| Feature | Free Solutions | Premium Solutions |
|---|---|---|
| Voice Quality | Basic synthesis | Neural-powered, natural |
| Character Limits | 500-5,000 per month | Unlimited or high limits |
| Voice Options | 2-10 voices | 50+ voices |
| Commercial Use | Often restricted | Full licensing |
| API Access | Limited or none | Full API capabilities |
Premium platforms justify their cost through superior neural text to speech technology, extensive customization options, and robust support systems. Enterprise solutions offer additional benefits including priority processing, dedicated support teams, and compliance with industry standards such as HIPAA or GDPR.
Integration and Technical Requirements
API capabilities determine how easily you can integrate text to speech ai functionality into existing workflows and applications. Look for RESTful APIs with comprehensive documentation, SDKs for popular programming languages, and webhook support for real-time processing notifications.
Platform compatibility affects deployment flexibility and user accessibility. Cloud-based solutions offer scalability and reduced infrastructure requirements, while on-premise options provide greater control over data security and processing latency. Consider whether you need mobile app integration, web browser compatibility, or desktop application support.
Evaluate processing speed and concurrent user support, especially for applications requiring real-time voice generation. Some platforms excel at batch processing large documents, while others optimize for immediate response times in interactive applications.
Security features become critical for sensitive content or regulated industries. Examine data encryption protocols, storage policies, and compliance certifications. Many enterprise-grade ai voice synthesis platforms offer zero-retention policies where processed text is immediately deleted after conversion.
Consider the total cost of ownership including API call pricing, bandwidth requirements, and potential scaling costs as your usage grows. Factor in technical support quality, documentation completeness, and the vendor’s track record for service reliability when making your final selection.
Future of AI Text to Speech Technology
The landscape of text to speech ai technology is evolving at an unprecedented pace, driven by breakthrough innovations in neural networks, real-time processing capabilities, and increasingly sophisticated voice synthesis models. As we look toward the future, several transformative trends are reshaping how we interact with AI-generated speech across industries and applications.
Emerging Trends and Innovations
Neural text to speech systems are becoming remarkably more human-like, with emerging models capable of conveying subtle emotional nuances, regional accents, and speaking styles that were previously impossible to replicate. Advanced ai voice synthesis now incorporates contextual understanding, allowing systems to adjust tone, pace, and emphasis based on the content’s meaning rather than just phonetic rules.
Real-time voice cloning represents another significant advancement, where ai text to speech systems can learn and replicate individual voice characteristics from minimal audio samples. This technology enables personalized voice assistants, custom audiobook narrations, and accessibility solutions that maintain the user’s original voice patterns even after speech impairment.
Cross-lingual voice synthesis is breaking down language barriers, with text to voice ai systems capable of speaking multiple languages while maintaining consistent vocal identity. These multilingual capabilities are particularly valuable for global businesses, educational platforms, and content creators seeking to reach diverse audiences without sacrificing voice consistency.
Industry Impact and Adoption
Market projections indicate that the global text to speech market will experience substantial growth, driven by increased adoption across healthcare, education, entertainment, and customer service sectors. Healthcare organizations are integrating ai text to speech technology into electronic health records, enabling hands-free documentation and improving clinical workflow efficiency.
The entertainment industry is leveraging neural text to speech for dynamic content creation, including interactive gaming experiences where characters can generate unique dialogue in real-time. Publishing houses are using these technologies to rapidly produce audiobook versions of written content, significantly reducing production timelines and costs.
Educational institutions are implementing text to voice ai solutions to support students with learning differences, creating more inclusive learning environments. Corporate training programs are adopting these technologies to deliver consistent, scalable voice-based instruction across global teams.
Ethical Considerations and Best Practices
As ai voice synthesis becomes more sophisticated, addressing privacy and consent issues becomes increasingly critical. Organizations must establish clear protocols for voice data collection, storage, and usage, ensuring individuals maintain control over their vocal identity and how it may be replicated or modified.
Responsible ai text to speech implementation requires transparent disclosure when synthetic voices are used in content creation, customer interactions, or media production. This transparency helps maintain trust while preventing potential misuse for deceptive purposes or unauthorized voice replication.
Industry leaders are developing ethical frameworks that balance innovation with user protection, including guidelines for consent mechanisms, data retention policies, and voice authentication systems. These standards will likely become regulatory requirements as governments recognize the need to govern synthetic voice technologies.
The future success of text to speech ai technology depends on maintaining this balance between technological advancement and ethical responsibility, ensuring that these powerful tools enhance human communication while respecting individual rights and societal values.
