
The digital landscape has been transformed by text to voice generator technology, turning written content into natural-sounding speech with remarkable precision. What once required expensive studio equipment and professional voice actors can now be accomplished instantly through AI voice generation platforms that deliver human-like narration for everything from educational videos to accessibility solutions. This revolutionary shift has democratized audio content creation, enabling businesses, educators, and content creators to reach broader audiences while making digital information accessible to users with visual impairments or reading difficulties.
Modern speech synthesis has evolved far beyond robotic-sounding outputs of the past. Today’s text to speech generator tools leverage advanced neural networks and machine learning algorithms to produce voices that capture natural intonation, emotion, and speaking patterns. These sophisticated voice synthesis systems have become indispensable for multimedia production, e-learning platforms, podcast creation, and customer service automation, fundamentally changing how we consume and interact with digital content.
This comprehensive guide explores everything you need to know about text to voice technology, from understanding core functionalities and essential features to selecting the right platform for your specific needs. You’ll discover practical applications, professional techniques for optimizing audio quality, and emerging trends that will shape the future of AI-powered voice generation.
What Are Text to Voice Generators and How Do They Work
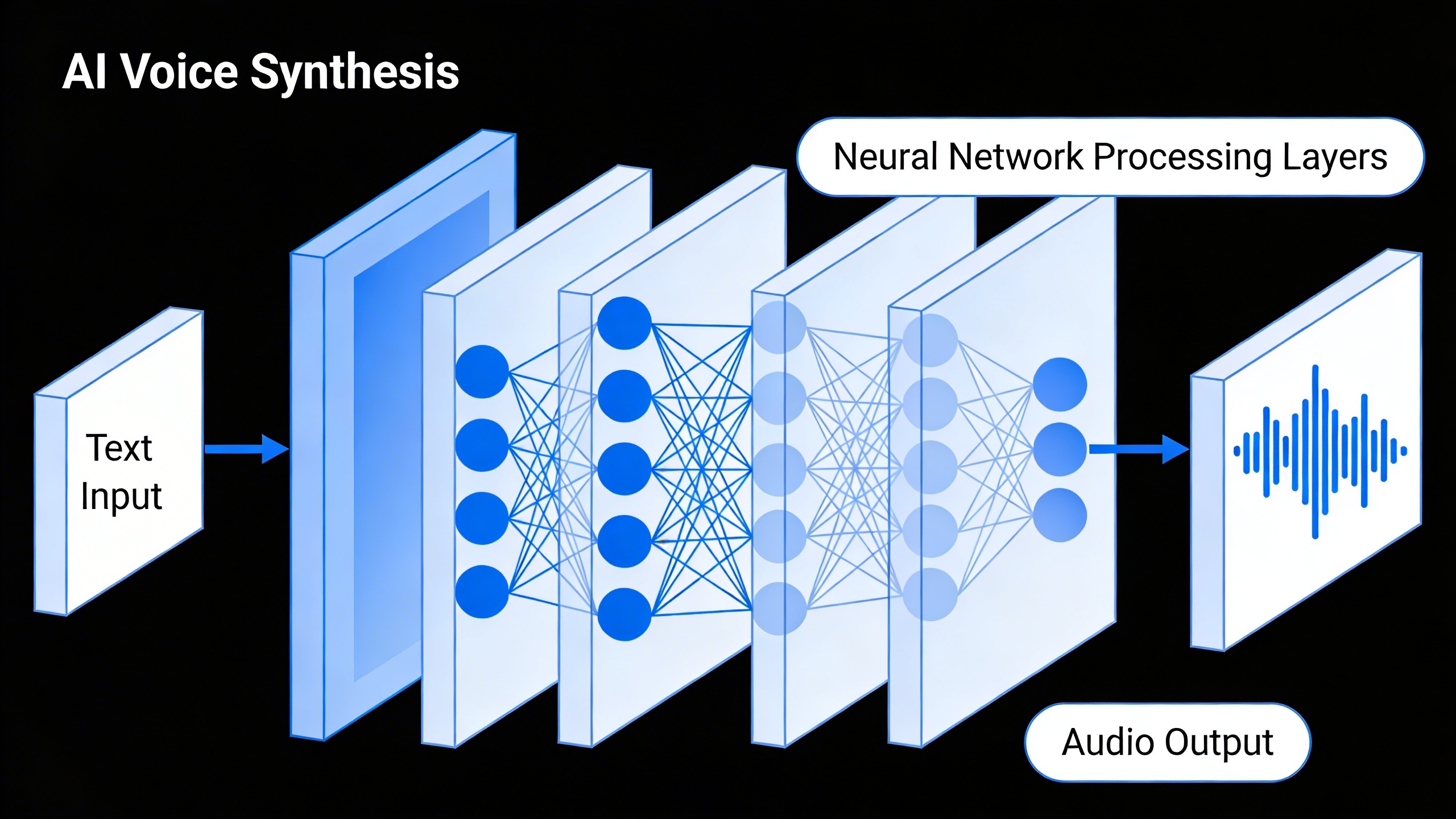
A text to voice generator is a sophisticated software system that converts written text into spoken audio using artificial intelligence and advanced speech synthesis techniques. These powerful tools analyze written content, understand linguistic patterns, and produce natural-sounding speech that closely mimics human vocal characteristics. Modern text to speech generator technology has evolved far beyond the robotic, monotone voices of early systems, now delivering remarkably lifelike audio that can convey emotion, emphasis, and nuanced pronunciation.
The transformation from text to speech involves complex computational processes that happen in milliseconds. When you input text into a voice synthesis system, the software first analyzes the written content for linguistic elements like punctuation, capitalization, and context clues. It then applies phonetic rules, determines proper pronunciation for each word, and generates corresponding audio waveforms that produce intelligible speech through speakers or headphones.
Understanding Voice Synthesis Technology
Voice synthesis technology operates on multiple layers of artificial intelligence that work together to create authentic-sounding speech. The foundation relies on deep learning models trained on vast datasets of human speech patterns, enabling systems to understand how different phonemes, syllables, and words should sound when spoken aloud. These models learn from thousands of hours of recorded human speech, capturing subtle variations in tone, rhythm, and pronunciation that make synthetic voices sound increasingly natural.
Modern AI voice generation systems utilize neural networks that can process linguistic context, ensuring that homonyms are pronounced correctly based on surrounding words. For example, the system understands that “read” should sound different in “I read books daily” versus “I read that book yesterday.” This contextual awareness represents a significant advancement over rule-based systems that relied on predetermined pronunciation dictionaries.
The technology also incorporates prosodic modeling, which controls the rhythm, stress, and intonation of synthetic speech. This allows text to speech generator systems to add appropriate emphasis, pause at commas and periods, and adjust speaking pace based on punctuation and sentence structure. Advanced systems can even detect emotional context from the text and adjust vocal characteristics accordingly.
AI-Powered Speech Generation Process
The speech synthesis process begins with text preprocessing, where the system normalizes written input by expanding abbreviations, converting numbers to words, and handling special characters. The AI then performs linguistic analysis to determine proper pronunciation, stress patterns, and grammatical structure. This step is crucial for handling complex words, foreign terms, and technical vocabulary that might not follow standard pronunciation rules.
Next, the system generates phonetic representations of the text, creating a detailed map of how each sound should be produced. Advanced neural networks then convert these phonetic sequences into acoustic features, determining characteristics like pitch, volume, and timing for each sound segment. The final step involves audio synthesis, where the system generates actual sound waveforms that can be played through audio devices.
Machine learning algorithms continuously refine this process by analyzing feedback and improving pronunciation accuracy. Some systems can even adapt to specific speaker characteristics, allowing users to create custom voices that match particular vocal qualities or speaking styles.
Key Components of Modern TTS Systems
Contemporary text to voice generator systems consist of several integrated components that work seamlessly together. The text analyzer serves as the first processing layer, handling input normalization and linguistic preprocessing. The phonetic engine converts written words into phonetic representations, while the prosody generator determines appropriate rhythm and intonation patterns.
The neural vocoder represents the most advanced component, using deep learning to generate high-quality audio waveforms from phonetic and prosodic information. This component distinguishes modern AI-powered systems from older concatenative approaches that pieced together pre-recorded speech segments.
Modern systems also include voice modeling capabilities that can simulate different speaker characteristics, ages, and speaking styles. Some platforms offer real-time processing for immediate audio output, while others use batch processing for handling large volumes of text efficiently. The choice between real-time and batch processing depends on specific use cases, with real-time systems ideal for interactive applications and batch processing better suited for content creation workflows.
Essential Features of Modern Text to Speech Generators
The effectiveness of any text to voice generator depends heavily on its core features and capabilities. Today’s advanced speech synthesis platforms offer sophisticated tools that transform written content into remarkably human-like audio, but understanding which features matter most can help you select the right solution for your specific needs.
Voice Quality and Natural Speech Patterns
The hallmark of an exceptional text to speech generator lies in its ability to produce voices that sound genuinely human rather than robotic. Modern AI voice generation systems achieve this through neural networks trained on vast datasets of human speech patterns, resulting in voices that capture the subtle nuances of natural conversation.
Voice clarity serves as the foundation of quality speech synthesis. Premium platforms maintain consistent audio clarity across different text lengths and complexity levels, ensuring that every word remains crisp and intelligible. The best systems also handle punctuation intelligently, incorporating appropriate pauses for commas, periods, and question marks that mirror natural speaking rhythms.
Prosody—the rhythm, stress, and intonation of speech—distinguishes superior voice synthesis from basic alternatives. Advanced text to voice generators analyze sentence structure and context to apply appropriate emphasis, making statements sound confident and questions genuinely inquisitive. This contextual understanding prevents the monotone delivery that characterizes older speech synthesis technologies.
Emotional range represents another crucial quality metric. Modern AI voice generation can detect and convey different emotional tones based on text content, whether expressing excitement in marketing copy or maintaining professionalism in business communications. This emotional intelligence makes generated speech more engaging and appropriate for diverse applications.
Customization and Voice Selection Options
Versatile voice selection capabilities enable users to match audio output with their specific audience and content requirements. Leading text to speech generators offer extensive voice libraries featuring different ages, genders, accents, and speaking styles. Professional platforms typically provide 50 or more distinct voices, ensuring suitable options for educational content, entertainment, accessibility applications, and business communications.
Language support extends far beyond basic English options in comprehensive speech synthesis platforms. The most capable systems support dozens of languages with region-specific accents and dialects. This multilingual functionality proves essential for global businesses, educational institutions, and content creators serving diverse audiences.
Character voice options add creative flexibility for storytelling and entertainment applications. Some text to voice generators include specialized character voices designed for audiobooks, podcasts, or interactive content, allowing creators to assign distinct voices to different speakers or characters within their projects.
Voice cloning technology, available in select premium platforms, enables users to create custom voices based on sample recordings. This advanced feature proves valuable for brands seeking consistent voice representation across all audio content or individuals requiring personalized accessibility solutions.
Advanced Controls and Audio Settings
Granular control over speech parameters allows users to fine-tune audio output for specific requirements. Speed adjustment capabilities let you optimize pacing for different audiences—slower speeds benefit language learners or accessibility users, while faster delivery suits time-sensitive applications or users who prefer accelerated content consumption.
Pitch modification tools enable further voice customization without compromising naturalness. Quality text to speech generators maintain voice clarity and emotional expression across different pitch ranges, allowing users to adjust tone while preserving the authentic character of the selected voice.
Pronunciation controls address one of the most challenging aspects of automated speech synthesis. Advanced platforms include phonetic spelling options, custom pronunciation dictionaries, and the ability to specify pronunciation for technical terms, proper names, or industry-specific vocabulary that standard algorithms might misinterpret.
SSML (Speech Synthesis Markup Language) support provides professional-grade control over speech output. This standardized markup language allows precise specification of pauses, emphasis, pronunciation, and other speech characteristics directly within the text. SSML capabilities prove particularly valuable for creating polished audio content that requires specific timing or emphasis patterns.
Audio format options ensure compatibility with various platforms and applications. Modern voice synthesis platforms typically support multiple output formats including MP3, WAV, and OGG, with adjustable quality settings to balance file size and audio fidelity based on intended usage.
Batch processing functionality streamlines workflow for users handling large volumes of content. This feature allows simultaneous conversion of multiple documents or text segments, significantly improving efficiency for content creators, educators, and businesses requiring regular audio content production.

Top Applications and Use Cases for Voice Generation
Modern text to voice generator technology has revolutionized how we consume and interact with digital content across numerous industries. From enhancing accessibility to streamlining business operations, voice synthesis applications continue to expand as AI voice generation becomes more sophisticated and natural-sounding.
Content Creation and Marketing
The content creation landscape has been transformed by advanced speech synthesis technology. Video producers and marketers now rely on text to speech generators to create professional narration without the need for expensive voice talent or recording equipment. YouTube creators, for instance, can produce consistent, high-quality voiceovers for educational content, product demonstrations, and explainer videos in multiple languages.
Podcast production has similarly benefited from AI voice generation tools. Content creators can generate intro segments, advertisement reads, or even entire episodes using synthetic voices that maintain consistent tone and pacing. This approach proves particularly valuable for businesses producing regular podcast content where scheduling human narrators becomes challenging.
Marketing teams leverage voice synthesis for creating audio advertisements, social media content, and interactive voice responses. The ability to quickly iterate on messaging and test different vocal styles without re-recording allows for more agile campaign development and optimization.
Accessibility and Educational Applications
Text to voice generators serve as fundamental tools for digital accessibility, particularly through screen reader technology. Visually impaired users depend on these systems to navigate websites, read documents, and interact with digital interfaces. Modern speech synthesis engines provide natural intonation and pronunciation that significantly improves comprehension compared to earlier robotic-sounding alternatives.
Educational institutions have embraced AI voice generation for creating inclusive learning environments. Students with dyslexia, visual impairments, or reading difficulties benefit from having textbooks, assignments, and research materials converted to audio format. This technology enables educators to provide multimodal learning experiences that accommodate different learning preferences and needs.
Language learning applications utilize text to speech generators to provide pronunciation examples and conversational practice. Students can hear proper pronunciation of foreign words and phrases, while teachers can create audio exercises without requiring native speakers for every lesson.
Business and Professional Communications
Customer service operations have been revolutionized through voice synthesis integration. Interactive voice response systems now provide more natural-sounding automated assistance, improving customer experience while reducing operational costs. Call centers use text to voice generators to create consistent messaging across different representatives and time zones.
Training and development departments leverage speech synthesis technology to produce standardized training materials. Corporate e-learning modules, safety briefings, and onboarding content can be quickly updated and distributed with consistent vocal delivery. This approach ensures uniform message delivery while reducing production timelines and costs.
Professional presentations and webinars benefit from AI voice generation when live speakers are unavailable. Sales teams can create product demonstrations, while HR departments can develop orientation materials that maintain professional quality regardless of presenter availability.
Internal communications also utilize text to speech generators for creating audio newsletters, policy updates, and company announcements. This enables organizations to reach employees who prefer audio content or work in environments where reading text is impractical.
The versatility of modern voice synthesis technology continues to unlock new applications across industries, making digital content more accessible, engaging, and cost-effective to produce.
Choosing the Right Text to Voice Generator for Your Needs
Selecting the ideal text to voice generator requires careful consideration of your specific requirements, budget constraints, and technical environment. The market offers dozens of solutions ranging from free basic tools to enterprise-grade platforms, each with distinct advantages for different use cases.
Evaluating Voice Quality and Natural Sound
Voice quality represents the most critical factor when choosing a speech synthesis solution. Modern AI voice generation has reached remarkable sophistication, but significant differences exist between providers. Listen for naturalness in pronunciation, proper emphasis on key words, and smooth transitions between sentences.
Test your chosen text to speech generator with various content types including technical terms, foreign words, and conversational text. Pay attention to how the system handles punctuation marks, as these directly impact the flow and comprehension of generated speech. The best solutions produce voices that sound genuinely human rather than robotic or monotone.
Consider the range of available voices, including different accents, genders, and speaking styles. Professional applications often require multiple voice options to match brand personality or target audience preferences. Some platforms offer custom voice training, allowing you to create unique vocal characteristics that align with your specific needs.
Comparing Pricing Models and Features
Text to voice generator pricing varies dramatically based on usage volume, feature set, and deployment options. Free solutions typically impose character limits, watermarks, or restricted commercial usage rights. These work well for personal projects or initial testing but may not suit professional applications.
Premium services usually offer tiered pricing based on monthly character allowances or per-word costs. Enterprise solutions often include unlimited usage, priority support, and advanced customization options. Calculate your expected monthly volume to determine the most cost-effective approach.
| Pricing Model | Best For | Typical Features |
|---|---|---|
| Free Tier | Personal use, testing | Basic voices, limited characters |
| Pay-per-use | Irregular usage | No monthly commitment, variable costs |
| Subscription | Regular content creation | Predictable costs, premium voices |
| Enterprise | Large-scale deployment | Custom integration, dedicated support |
Examine feature differences carefully, as some providers charge extra for SSML support, multiple file formats, or commercial licensing. Factor in potential scaling costs as your usage grows over time.
Technical Requirements and Integration Options
Your technical environment significantly influences which voice synthesis solution will work best. Cloud-based platforms offer convenience and automatic updates but require consistent internet connectivity. Desktop applications provide offline functionality and potentially faster processing for large volumes of content.
API availability becomes crucial for developers integrating speech synthesis into applications or websites. Look for comprehensive documentation, multiple programming language support, and reliable uptime guarantees. Some platforms offer webhook support for automated workflows, while others provide real-time streaming capabilities for interactive applications.
File format compatibility affects how easily you can use generated audio across different platforms. Standard formats like MP3 and WAV ensure broad compatibility, while some specialized applications may require specific audio codecs or quality settings. Consider whether you need batch processing capabilities for handling multiple files simultaneously.
Security and privacy requirements may dictate whether cloud or on-premises solutions work better for your organization. Healthcare, legal, and financial industries often require data residency controls and encryption standards that not all providers support.
Integration complexity varies widely between solutions. Some offer simple copy-paste functionality, while others require substantial development work. Evaluate your team’s technical capabilities and available resources before committing to complex implementations that may exceed your current skill set or timeline constraints.
Best Practices for Creating High-Quality Voice Content
Creating professional-grade voice content requires more than just selecting a quality text to voice generator. The difference between amateur and professional results lies in understanding how to prepare your content, optimize audio output, and maintain consistent quality standards throughout your production process.
Optimizing Text for Voice Generation
The foundation of exceptional voice synthesis begins with properly formatted text. Modern AI voice generation systems perform best when they can interpret clear structural cues and natural language patterns. Start by writing in a conversational tone that mirrors how people actually speak, avoiding overly complex sentence structures that can confuse speech synthesis algorithms.
Pay careful attention to punctuation as your primary tool for controlling pacing and emphasis. Use commas to create natural pauses, periods for definitive stops, and question marks to trigger appropriate intonation patterns. Ellipses (…) can signal longer pauses, while em dashes work well for dramatic breaks or clarifications. Numbers should be written out when possible, as “twenty-five” produces more natural speech than “25” in most text to speech generators.
Consider phonetic spelling for challenging words, proper names, or technical terms. Many platforms allow custom pronunciation guides, so create a glossary for frequently used specialized vocabulary. This ensures consistency across all your voice content and prevents awkward mispronunciations that can undermine your message.
Audio Post-Processing and Enhancement
Raw output from even the best text to voice generator typically benefits from post-processing refinement. Begin with noise reduction to eliminate any background artifacts or digital noise that may have been introduced during synthesis. Most audio editing software includes noise reduction tools that can clean up your voice files without affecting the natural speech characteristics.
Normalize audio levels to ensure consistent volume throughout your content. This prevents jarring volume changes that can distract listeners and creates a more professional listening experience. Apply gentle compression to smooth out any unnatural volume spikes while preserving the dynamic range that makes speech engaging.
Consider adding subtle reverb or room tone to make synthetic voices feel more natural and less clinical. However, use these effects sparingly—the goal is to enhance realism without drawing attention to the processing itself.
Quality Control and Testing Methods
Implement systematic quality control processes to maintain consistent standards across all your voice content. Start with A/B testing different voice models and settings using the same text sample. This helps you identify which combinations of voice, speed, and pitch work best for your specific content type and target audience.
Create a standardized checklist covering pronunciation accuracy, natural pacing, appropriate emphasis, and overall clarity. Test your content with actual listeners from your target demographic, as they often catch issues that creators miss after repeated exposure to the same material.
Establish quality benchmarks for different content types. Educational content may prioritize clarity and deliberate pacing, while marketing materials might emphasize energy and persuasive tone. Document these standards to ensure consistency as your team grows or when working with multiple voice synthesis platforms.
Regular quality audits help identify patterns in common issues, allowing you to refine your text preparation and processing workflows. This systematic approach transforms voice generation from a technical task into a refined content creation skill that consistently delivers professional results.
Advanced Techniques and Professional Tips
Mastering advanced text to voice generator capabilities can dramatically improve your workflow efficiency and output quality. These professional-grade techniques separate casual users from power users who leverage voice synthesis technology to its full potential.
Custom Voice Training and Cloning
Modern AI voice generation platforms allow you to create custom voice models that match specific brand requirements or personal preferences. Voice cloning typically requires 10-30 minutes of high-quality audio samples from the target speaker, recorded in a quiet environment with consistent tone and pacing.
Start with shorter phrases covering diverse phonetic patterns before progressing to longer sentences. The training process involves feeding these samples into neural networks that learn vocal characteristics, breathing patterns, and speech rhythms. Professional voice cloning delivers remarkable results for corporate training videos, audiobook narration, and personalized customer experiences.
When implementing custom voices, consider legal and ethical implications. Always obtain explicit consent from voice donors and clearly disclose when synthetic voices are being used in public-facing content.
Batch Processing and Workflow Automation
Efficient speech synthesis workflows rely heavily on batch processing capabilities. Most enterprise-grade text to speech generators support bulk conversion through CSV uploads, API endpoints, or dedicated desktop applications.
Structure your content with consistent formatting before batch processing. Use standardized tags for emphasis, pauses, and pronunciation guides across all documents. This approach ensures uniform output quality when converting hundreds or thousands of text files simultaneously.
Implement automated workflows using tools like Zapier or custom scripts that trigger voice generation when new content appears in designated folders or databases. Schedule batch processing during off-peak hours to optimize system resources and reduce processing costs.
Integration with Content Management Systems
Seamless CMS integration transforms how organizations handle voice content creation. Popular platforms like WordPress, Drupal, and custom solutions support text to voice generator plugins that automatically create audio versions of published articles.
Configure webhook triggers that initiate voice synthesis whenever content editors publish new posts or pages. This automation ensures your audio content library stays synchronized with written materials without manual intervention.
| CMS Platform | Integration Method | Key Benefits |
|---|---|---|
| WordPress | Plugin + API | Automatic post conversion, player embedding |
| Drupal | Custom module | Advanced field mapping, multilingual support |
| Custom CMS | REST API | Complete workflow control, branded experience |
API implementation requires careful rate limiting and error handling to prevent service disruptions. Monitor usage patterns and implement caching strategies to optimize performance while managing costs effectively. These advanced techniques enable scalable voice content production that grows with your organization’s needs.
Future Trends and Emerging Technologies in Voice Synthesis
The landscape of voice synthesis technology continues to evolve at an unprecedented pace, with breakthrough innovations reshaping how we interact with digital content. These advancements promise to make text to voice generators more accessible, natural, and versatile than ever before.
AI Advancements in Natural Speech
Modern machine learning algorithms are revolutionizing speech synthesis by creating voices that capture subtle human nuances previously impossible to replicate. Neural networks now analyze vast datasets of human speech patterns, enabling text to speech generators to produce conversations that include natural pauses, breathing sounds, and contextual emphasis. These AI voice generation systems can adapt pronunciation based on sentence context, automatically adjusting tone for questions versus statements.
Emotional expression represents the next frontier in voice synthesis technology. Advanced models can now interpret emotional context from written text, automatically adjusting vocal characteristics to convey excitement, concern, or empathy. This capability transforms static content into engaging narratives that resonate with listeners on a deeper level.
Real-Time Voice Generation Capabilities
Low-latency processing has become a game-changer for interactive applications requiring immediate voice output. Modern text to voice generators can now process and synthesize speech in under 100 milliseconds, enabling seamless integration into live conversations, gaming environments, and real-time customer service applications.
Edge computing technology allows voice synthesis to occur directly on user devices, eliminating internet dependency and ensuring privacy-sensitive content remains secure. This advancement opens possibilities for offline voice generation in mobile apps, smart devices, and professional environments where data security is paramount.
Multilingual and Cross-Cultural Applications
Global accessibility features are expanding rapidly, with speech synthesis systems now supporting over 100 languages and regional dialects. These multilingual capabilities extend beyond simple translation, incorporating cultural speech patterns, local expressions, and region-specific pronunciation variations.
Cross-cultural voice adaptation technology enables a single text to speech generator to maintain consistent personality traits across different languages while respecting cultural communication norms. This breakthrough facilitates international content creation, educational materials, and global business communications.
Voice cloning technology is becoming more sophisticated and ethical, with systems capable of creating personalized voices from minimal audio samples while implementing safeguards against misuse. These developments will democratize voice synthesis, allowing individuals and organizations to create unique vocal identities that reflect their brand or personal style.
