
Speech recognition technology has transformed from a futuristic concept into an essential component of our daily digital interactions. This sophisticated AI-powered process converts spoken language into written text with remarkable accuracy, enabling everything from voice commands on smartphones to real-time transcription of business meetings. What began as basic voice detection systems in the 1950s has evolved into advanced automatic speech recognition platforms that understand context, accents, and even emotional nuances in human speech.
Today’s voice recognition systems power a vast ecosystem of applications, from accessibility tools that help individuals with disabilities to productivity solutions that streamline workflows across industries. Whether you’re dictating notes during a commute, conducting virtual meetings, or developing voice-enabled applications, understanding how speech recognition works has become crucial for leveraging these powerful technologies effectively.
This comprehensive guide will walk you through the fundamentals of voice speech recognition, explore how these systems process and interpret human language, and examine the practical applications reshaping industries worldwide. You’ll discover the key benefits driving adoption, learn about current limitations, and gain insights into choosing the right speech detection solution for your specific needs.
What is Speech Recognition Technology?
Speech recognition technology, also known as automatic speech recognition (ASR), is a sophisticated artificial intelligence system that converts spoken language into written text. This transformative technology analyzes audio signals containing human speech and translates them into digital text format, enabling computers to understand and process verbal communication. At its foundation, speech recognition systems combine advanced signal processing, machine learning algorithms, and linguistic models to achieve accurate voice-to-text conversion.
The technology works by capturing audio input through microphones or recording devices, then processing these sound waves through multiple computational layers. Modern speech recognition systems can handle various accents, speaking speeds, and background noise levels, making them increasingly practical for real-world applications ranging from virtual assistants to medical transcription services.
Core Components and Architecture
Automatic speech recognition systems rely on two fundamental components that work together to achieve accurate transcription: acoustic modeling and language processing. The acoustic model analyzes the physical properties of speech sounds, converting audio waveforms into phonetic representations. This component identifies individual sounds, syllables, and words by examining frequency patterns, amplitude variations, and temporal characteristics within the audio signal.
Language processing, the second critical component, applies grammatical rules and contextual understanding to improve transcription accuracy. This element uses statistical models and neural networks to predict the most likely word sequences based on linguistic patterns and semantic relationships. The language model considers factors such as word probability, sentence structure, and contextual meaning to resolve ambiguities that might arise during the acoustic analysis phase.
Modern speech recognition architectures typically incorporate deep learning frameworks, including recurrent neural networks (RNNs) and transformer models. These advanced systems can learn from vast datasets of spoken language, continuously improving their ability to handle diverse speaking styles, vocabulary variations, and complex linguistic structures.
Types of Speech Recognition Systems
Speech recognition technology encompasses several distinct system types, each designed for specific use cases and performance requirements. Speaker-dependent systems require initial training with a particular user’s voice patterns, creating personalized acoustic models that achieve high accuracy for that individual speaker. These systems excel in controlled environments where consistent users interact with the technology regularly.
Speaker-independent systems, conversely, function effectively without prior voice training, accommodating multiple users with varying speech characteristics. These versatile systems use generalized acoustic models trained on diverse speech datasets, making them suitable for public-facing applications and multi-user environments.
| System Type | Training Required | Accuracy | Best Use Cases |
|---|---|---|---|
| Speaker-Dependent | Yes, per user | Very High | Personal assistants, dictation software |
| Speaker-Independent | No | High | Call centers, public kiosks |
| Speaker-Adaptive | Minimal | Very High | Long-term personal use applications |
Speaker-adaptive systems represent a hybrid approach, beginning with speaker-independent capabilities and gradually adapting to individual users over time. This technology combines the immediate usability of speaker-independent systems with the personalized accuracy of speaker-dependent models.
How Voice Recognition Differs from Speech Recognition
While often used interchangeably, voice recognition and speech recognition serve distinctly different purposes within audio processing technology. Speech recognition focuses on converting spoken words into text, emphasizing the content and meaning of verbal communication. This technology prioritizes understanding what was said, regardless of who spoke the words.
Voice recognition, however, concentrates on identifying the speaker rather than transcribing their words. This biometric technology analyzes unique vocal characteristics such as pitch, tone, accent, and speaking patterns to authenticate individual users. Voice recognition systems create voiceprints that serve as audio-based identification methods, similar to fingerprints or facial recognition.
Speech detection represents another related but distinct concept, referring to the initial identification of speech activity within audio streams. This preliminary process distinguishes between speech and non-speech audio segments, enabling more efficient processing by focusing computational resources on relevant audio portions. Voice speech recognition systems often combine these technologies, using speech detection to identify when someone is speaking, speech recognition to transcribe the content, and voice recognition to identify the speaker.
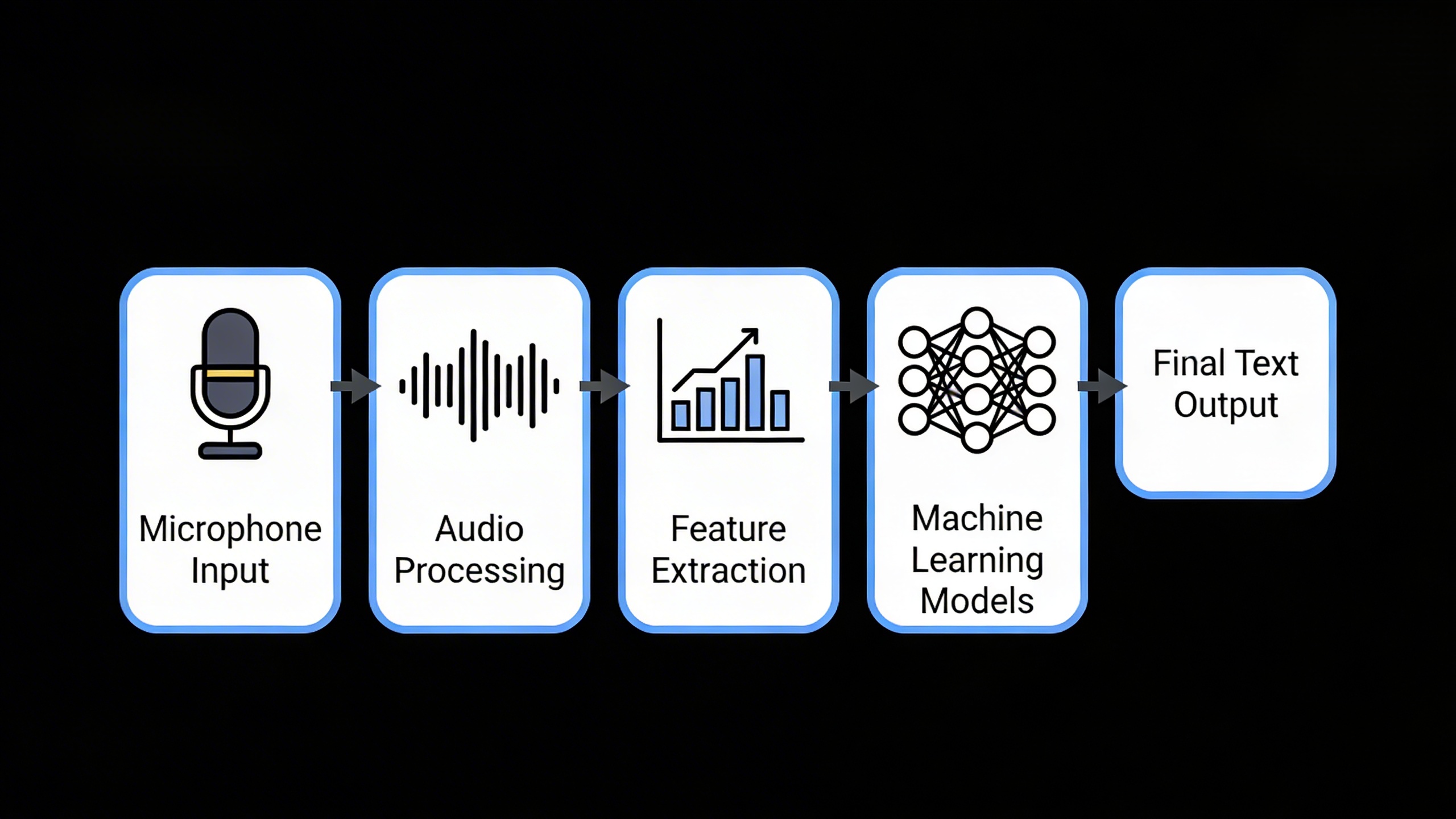
How Speech Recognition Technology Works
Understanding the inner workings of automatic speech recognition reveals a sophisticated multi-stage process that transforms raw audio waves into accurate text output. Modern speech recognition systems rely on advanced computational techniques that process, analyze, and interpret human speech with remarkable precision.
Audio Signal Processing and Feature Extraction
The journey from spoken words to digital text begins when a microphone captures sound waves and converts them into electrical signals. These analog signals undergo immediate digitization, creating a numerical representation of the audio that computers can process. The system then applies pre-processing techniques to enhance signal quality, removing background noise and normalizing volume levels.
During feature extraction, the speech recognition engine analyzes the audio signal to identify distinctive characteristics that differentiate one sound from another. The system breaks down the continuous audio stream into small time frames, typically 10-25 milliseconds each, and examines the frequency content within each frame. This process creates a spectral representation that highlights important acoustic features like formants, pitch patterns, and energy distributions.
Advanced voice recognition systems employ mel-frequency cepstral coefficients (MFCCs) to capture the most relevant acoustic information while discarding redundant data. These mathematical transformations help the system focus on speech-specific frequencies that human ears perceive most clearly, improving both processing efficiency and recognition accuracy.
Machine Learning Models and Neural Networks
Modern automatic speech recognition systems rely heavily on deep learning architectures, particularly recurrent neural networks (RNNs) and transformer models. These sophisticated algorithms learn to map acoustic features to linguistic units through exposure to vast amounts of training data containing paired audio recordings and their corresponding transcriptions.
The most successful contemporary systems employ end-to-end neural architectures that eliminate the need for separate acoustic and language models. These unified approaches, such as attention-based sequence-to-sequence models, can directly convert audio features into text sequences. The attention mechanism allows the model to focus on relevant parts of the input audio when generating each word, significantly improving accuracy for longer utterances.
Convolutional neural networks often handle initial feature processing, while transformer layers manage the complex task of understanding temporal dependencies and linguistic context. This combination enables voice speech recognition systems to handle variations in accent, speaking speed, and background conditions that would challenge traditional rule-based approaches.
Training these models requires enormous datasets containing millions of hours of diverse speech samples. The learning process involves adjusting billions of parameters to minimize prediction errors, gradually improving the system’s ability to recognize speech patterns across different speakers, languages, and acoustic environments.
Real-Time Processing and Accuracy Optimization
Achieving real-time performance while maintaining high accuracy presents significant computational challenges. Speech detection systems must process audio streams with minimal latency, often requiring specialized hardware acceleration through graphics processing units (GPUs) or dedicated neural processing units.
Modern systems employ streaming architectures that begin processing audio segments before the speaker finishes talking. This approach, known as incremental decoding, allows for near-instantaneous transcription while maintaining the flexibility to revise earlier predictions based on additional context. The system continuously refines its output as more audio becomes available, balancing speed with accuracy.
Accuracy optimization involves multiple strategies working in concert. Language models trained on vast text corpora help the system understand probable word sequences and correct potential recognition errors. Confidence scoring mechanisms identify uncertain predictions, allowing the system to request clarification or flag potentially incorrect transcriptions.
Adaptive learning capabilities enable speech recognition systems to improve performance for specific users or domains over time. By analyzing correction patterns and user feedback, these systems can adjust their models to better handle individual speaking styles, specialized vocabulary, or unique acoustic environments.
The integration of contextual information, such as previous conversation history or document content, further enhances accuracy. This contextual awareness allows voice recognition systems to disambiguate homophones, expand abbreviations appropriately, and maintain consistency in terminology throughout longer transcription sessions.
Quality automatic speech recognition platforms combine all these technological components to deliver reliable, accurate transcription services that adapt to diverse user needs and speaking conditions.

Key Applications of Speech Recognition Technology
Speech recognition technology has transformed from a futuristic concept into an essential tool across multiple industries. Modern automatic speech recognition systems deliver accuracy rates exceeding 95% in optimal conditions, making them viable for mission-critical applications. Understanding where and how these voice-powered systems excel helps organizations identify opportunities to streamline operations and enhance user experiences.
Productivity and Business Solutions
The business world has embraced speech recognition as a powerful productivity multiplier. Meeting documentation represents one of the most impactful applications, where voice recognition systems automatically capture spoken discussions and convert them into searchable text transcripts. This eliminates the traditional bottleneck of manual note-taking and ensures complete accuracy in recording important decisions and action items.
Customer service departments leverage speech recognition to analyze call patterns, extract sentiment data, and automatically route inquiries based on spoken keywords. Sales teams use voice-to-text capabilities during client meetings to maintain eye contact while ensuring comprehensive record-keeping. The technology also powers hands-free email composition and document creation, allowing professionals to multitask effectively.
Modern transcription services have revolutionized how businesses handle audio content. Companies can now process hours of recorded meetings, interviews, and presentations in minutes rather than days. For organizations seeking reliable transcription capabilities, Sozai offers AI-powered speech detection that works seamlessly across devices, enabling teams to capture and organize spoken content efficiently.
Real-time collaboration benefits significantly from voice speech recognition integration. Virtual meeting platforms now offer live captioning and automatic summary generation, making remote work more accessible and productive. These systems can distinguish between multiple speakers, assign dialogue correctly, and even highlight key topics or decisions for easy reference.
Healthcare and Medical Documentation
Healthcare represents perhaps the most transformative application area for speech recognition technology. Medical professionals spend approximately 35% of their time on documentation tasks, creating a significant burden that voice recognition systems can substantially reduce. Physicians can now dictate patient notes, treatment plans, and diagnostic observations directly into electronic health records while maintaining focus on patient care.
Medical speech recognition software offers specialized vocabularies containing thousands of medical terms, drug names, and anatomical references. These systems understand complex medical terminology and can accurately transcribe procedures, symptoms, and treatment protocols. The technology also supports template-based documentation, where doctors can quickly populate standard forms through voice commands.
Emergency departments benefit particularly from hands-free documentation capabilities. Medical staff can update patient records while performing examinations or procedures, ensuring real-time accuracy without compromising care quality. Surgical teams use voice recognition to document procedures as they occur, creating detailed operative reports without requiring additional personnel.
The technology also enhances patient safety through medication verification systems that use speech recognition to confirm drug names, dosages, and administration instructions. This creates an additional verification layer that helps prevent medication errors, one of the leading causes of adverse events in healthcare settings.
Accessibility and Assistive Technology
Voice recognition programs serve as crucial accessibility tools for individuals with various disabilities. People with mobility limitations can control computers, smartphones, and smart home devices entirely through voice commands. This independence extends to complex tasks like document editing, web browsing, and application navigation.
For individuals with dyslexia or other learning differences, speech recognition provides an alternative input method that bypasses traditional typing challenges. Students can compose essays, complete assignments, and take notes using their natural speaking voice, often achieving better results than through conventional text input methods.
Visual impairment communities rely heavily on voice recognition technology for device interaction. Screen readers combined with speech recognition create comprehensive accessibility solutions that allow users to navigate digital environments effectively. These systems can interpret spoken commands and provide audio feedback, creating a complete voice-based computing experience.
Cognitive accessibility represents another critical application area. Individuals with conditions affecting fine motor skills or cognitive processing can use automatic speech recognition to maintain independence in daily digital tasks. The technology adapts to individual speech patterns and can accommodate variations in pronunciation, speaking pace, and vocal clarity.
Workplace accommodation programs increasingly incorporate voice recognition solutions to ensure equal employment opportunities. These implementations demonstrate how speech detection technology removes barriers and creates inclusive environments where individuals with disabilities can contribute their full potential to organizational success.

Benefits and Advantages of Voice Recognition Systems
The adoption of automatic speech recognition technology has transformed how individuals and organizations approach communication, documentation, and human-computer interaction. Modern voice recognition systems deliver measurable improvements across productivity, cost efficiency, and user accessibility, making them essential tools for contemporary digital workflows.
Enhanced Productivity and Efficiency
Voice recognition technology dramatically accelerates information processing and content creation. Professional transcriptionists typically type at 40-60 words per minute, while average speakers naturally communicate at 125-150 words per minute. This fundamental speed advantage means voice-to-text conversion can potentially triple documentation speed for many users.
Research indicates that professionals using speech recognition for email composition, report writing, and note-taking experience productivity gains ranging from 20% to 40%. Medical professionals, for instance, can complete patient documentation 30% faster when using voice speech recognition compared to traditional typing methods. Legal practitioners report similar improvements when dictating case notes, briefs, and correspondence.
The multitasking capabilities enabled by voice recognition create additional efficiency layers. Users can dictate while walking, driving, or performing other tasks, effectively expanding their productive hours. This flexibility proves particularly valuable for field workers, sales professionals, and executives who need to capture information while mobile.
Cost Reduction and Time Savings
Organizations implementing speech detection systems typically observe substantial return on investment within the first year of deployment. Healthcare facilities report cost savings of $3,000 to $5,000 per physician annually through reduced transcription services and faster documentation turnaround times.
Call centers utilizing automatic speech recognition for customer service routing and basic query handling reduce operational costs by 15-25% while improving response times. The technology eliminates the need for manual call categorization and enables instant access to customer information through voice commands.
Administrative overhead decreases significantly when employees can dictate meeting notes, emails, and reports rather than scheduling separate typing sessions. Companies report that middle management saves an average of 2-3 hours weekly on documentation tasks, translating to thousands of dollars in recovered productivity per employee annually.
Training costs also diminish as voice recognition systems require minimal user education compared to complex software interfaces. Most professionals achieve proficiency within days rather than weeks, reducing onboarding time and associated expenses.
Improved Accessibility and User Experience
Speech recognition technology serves as a critical accessibility tool for individuals with mobility limitations, repetitive strain injuries, or visual impairments. Voice-controlled interfaces enable full computer access for users who cannot operate traditional keyboards or mice effectively.
The inclusive design benefits extend beyond disability accommodation. Older adults often find voice recognition more intuitive than touchscreen navigation, while users with dyslexia may prefer dictating to writing. This broader accessibility improves user satisfaction and expands potential customer bases for businesses implementing voice recognition features.
Modern voice speech recognition systems support multiple languages and accents, making technology more accessible to diverse user populations. Real-time translation capabilities further break down communication barriers in global business environments.
User experience improvements manifest through reduced cognitive load and more natural interaction patterns. Speaking feels more natural than typing for most people, leading to increased user engagement and reduced technology-related stress. For professionals who frequently create content, tools like Sozai demonstrate how intuitive voice recognition can streamline workflows across multiple devices and platforms.
The cumulative effect of these advantages positions speech recognition as a transformative technology that delivers measurable benefits across productivity, cost efficiency, and user satisfaction metrics.
Challenges and Limitations in Speech Recognition
While speech recognition technology has made remarkable advances, it still faces significant challenges that can impact performance and user adoption. Understanding these limitations helps organizations make informed decisions about implementing voice recognition systems and sets realistic expectations for users.
Accuracy Issues and Environmental Factors
The accuracy of automatic speech recognition systems remains heavily dependent on environmental conditions and audio quality. Background noise presents one of the most persistent challenges, as competing sounds can interfere with speech detection algorithms. Open office environments, traffic noise, air conditioning systems, and multiple speakers can significantly reduce recognition accuracy.
Microphone quality and distance also play crucial roles in system performance. Voice recognition software typically performs best with high-quality, close-proximity microphones, but real-world scenarios often involve built-in device microphones or hands-free operation from several feet away. These conditions can introduce audio distortion, echo, and reduced signal clarity that challenge even sophisticated recognition engines.
Speech patterns themselves create additional complexity. Rapid speech, mumbling, or speaking with food or drinks can dramatically impact accuracy. Medical conditions affecting speech, such as speech impediments or respiratory issues, may require specialized training or alternative input methods. Many systems also struggle with overlapping speech in group conversations or meetings, making it difficult to isolate individual speakers.
Language Variations and Accent Recognition
Language diversity presents ongoing challenges for speech recognition systems, particularly in global applications. While major languages like English, Spanish, and Mandarin receive extensive development resources, many regional languages and dialects have limited support or accuracy rates.
Accent recognition remains problematic even within well-supported languages. Regional accents, non-native speaker patterns, and cultural pronunciation variations can significantly impact voice speech recognition performance. A system trained primarily on American English may struggle with Scottish, Indian, or Australian accents, leading to frustrating user experiences and reduced adoption.
Code-switching, where speakers alternate between languages within the same conversation, poses additional complexity. Multilingual environments common in international businesses or diverse communities require sophisticated language detection and switching capabilities that many current systems lack.
Technical vocabulary and industry-specific terminology also challenge general-purpose recognition systems. Medical, legal, and scientific fields use specialized language that requires custom training datasets and domain-specific models to achieve acceptable accuracy levels.
Privacy and Security Considerations
Voice recognition technology raises significant privacy concerns as it involves collecting, processing, and potentially storing sensitive audio data. Unlike text input, voice data contains biometric information that can identify individuals, making it particularly sensitive from a privacy perspective.
Data storage and transmission security present ongoing challenges. Voice samples processed by cloud-based speech recognition services must be encrypted during transmission and storage, but this adds complexity and potential points of vulnerability. Organizations handling sensitive information must carefully evaluate whether cloud-based or on-device processing better meets their security requirements.
Consent and transparency issues complicate implementation, particularly in environments where multiple people might be recorded. Meeting rooms, customer service interactions, and smart home devices require clear policies about when recording occurs, who has access to the data, and how long recordings are retained.
Regulatory compliance adds another layer of complexity, with regulations like GDPR, CCPA, and industry-specific requirements governing how voice data can be collected, processed, and shared. Organizations must implement robust data governance frameworks and provide users with control over their voice data.
False activation represents an additional security concern, where speech detection systems might inadvertently activate and record private conversations. This risk is particularly relevant for always-listening devices and voice assistants that must balance responsiveness with privacy protection.
Despite these challenges, ongoing technological advances continue to address many limitations through improved algorithms, better training datasets, and enhanced privacy-preserving techniques. Organizations implementing voice recognition systems should carefully assess these factors against their specific use cases and requirements.
Choosing the Right Speech Recognition Solution
Selecting the optimal speech recognition solution requires careful evaluation of multiple factors that align with your specific needs and technical requirements. The landscape of automatic speech recognition technology offers diverse options, from cloud-based APIs to on-device solutions, each with distinct advantages and trade-offs.
Evaluating Features and Capabilities
When assessing speech recognition solutions, accuracy rates serve as the primary benchmark, but contextual performance matters more than generic statistics. Look for systems that excel in your specific use case, whether that involves technical terminology, multiple speakers, or noisy environments. Real-time processing capabilities become crucial for live applications like customer service or meeting transcription, while batch processing may suffice for content creation workflows.
Language support and dialect recognition represent critical considerations, particularly for global applications. Advanced voice recognition systems should handle code-switching between languages and adapt to regional accents without significant accuracy degradation. Additionally, evaluate customization options such as vocabulary training, acoustic model adaptation, and domain-specific optimization that can enhance performance for specialized terminology.
Speaker identification and voice biometric capabilities add another layer of functionality for security-sensitive applications. Some solutions excel at distinguishing between multiple speakers in conversations, while others focus on individual user authentication through voice speech recognition patterns.
Integration Requirements and Compatibility
Technical integration complexity varies significantly across speech recognition platforms. RESTful APIs offer straightforward implementation for web applications, while SDK-based solutions provide deeper integration capabilities for mobile and desktop applications. Consider the development resources required for implementation, including documentation quality, code samples, and developer support availability.
Platform compatibility extends beyond basic API access to include operating system requirements, hardware dependencies, and network connectivity needs. Cloud-based solutions typically offer broader compatibility but require stable internet connections, while on-device speech detection systems provide offline functionality at the cost of reduced processing power and feature limitations.
Data security and privacy compliance requirements often dictate deployment preferences. On-premises solutions offer maximum control over sensitive audio data, while cloud services may provide superior accuracy through larger training datasets and continuous model improvements. Evaluate encryption protocols, data retention policies, and regulatory compliance certifications that align with your industry requirements.
Cost Considerations and Scalability
Pricing models for automatic speech recognition services vary from per-minute usage charges to flat-rate subscriptions and one-time licensing fees. Usage-based pricing suits applications with unpredictable volume, while subscription models provide cost predictability for steady workloads. Calculate total cost of ownership including development time, maintenance requirements, and potential scaling costs.
Scalability planning involves both technical and financial dimensions. Cloud-based voice recognition services typically handle traffic spikes automatically but may incur higher costs during peak usage periods. Self-hosted solutions require infrastructure planning and capacity management but offer more predictable long-term costs for high-volume applications.
Consider the learning curve and training requirements for your team. Some platforms offer intuitive interfaces and extensive documentation, while others may require specialized expertise. Factor in ongoing support costs, update frequencies, and the vendor’s roadmap for future enhancements when evaluating long-term viability.
For organizations seeking a balance of accuracy, ease of use, and comprehensive features, solutions like Sozai provide enterprise-grade speech recognition capabilities with straightforward implementation across multiple platforms, supporting both real-time transcription and batch processing workflows.
Future Trends in Speech Recognition Technology
The landscape of automatic speech recognition continues to evolve at an unprecedented pace, driven by breakthrough innovations in artificial intelligence and machine learning. As we look toward the future, several transformative trends are reshaping how voice recognition systems will integrate into our daily lives and professional workflows.
Emerging AI Advancements and Improvements
Neural network architectures are becoming increasingly sophisticated, enabling speech recognition systems to achieve near-human accuracy levels even in challenging acoustic environments. Transformer-based models and attention mechanisms are revolutionizing how these systems process and understand contextual speech patterns, leading to more natural and intuitive voice interactions.
Real-time processing capabilities are advancing rapidly, with edge computing allowing speech detection to occur locally on devices without cloud connectivity. This development addresses privacy concerns while reducing latency, making voice speech recognition more responsive and secure. Additionally, few-shot learning techniques are enabling systems to adapt quickly to new accents, dialects, and speaking patterns with minimal training data.
Multimodal AI integration represents another significant advancement, where speech recognition combines with computer vision and natural language processing to create more comprehensive understanding systems. These developments promise to deliver more accurate transcription services and enhanced user experiences across various applications.
Industry-Specific Innovations
Healthcare organizations are pioneering specialized voice recognition solutions that understand medical terminology and clinical workflows. These systems are becoming essential tools for physicians who need to document patient interactions efficiently while maintaining focus on patient care.
The automotive industry is implementing advanced speech recognition technology to create safer driving experiences through hands-free vehicle control and navigation systems. Voice-activated commands are becoming more sophisticated, understanding complex requests and providing contextual responses while drivers maintain attention on the road.
Educational institutions are exploring adaptive learning platforms that use automatic speech recognition to provide personalized language instruction and pronunciation feedback. These systems can analyze speaking patterns and provide targeted improvements for language learners across different proficiency levels.
Legal and business sectors are adopting specialized transcription solutions that handle industry-specific jargon and maintain high accuracy standards for documentation and compliance requirements.
Integration with Other Technologies
The convergence of speech recognition with Internet of Things devices is creating seamless smart home and office environments where voice commands control multiple connected systems simultaneously. This integration extends beyond simple device control to include complex automation scenarios and predictive assistance.
Augmented and virtual reality platforms are incorporating advanced voice recognition to enable natural communication within immersive environments. Users can interact with virtual objects and navigate digital spaces using intuitive speech commands, creating more engaging and accessible experiences.
Blockchain technology is beginning to intersect with voice recognition systems to provide secure authentication and verification methods. These developments could revolutionize how we approach voice-based identity confirmation and transaction authorization.
As these technologies mature, we can expect speech detection capabilities to become more contextually aware, emotionally intelligent, and seamlessly integrated into the fabric of digital interaction, fundamentally changing how humans communicate with technology.
